Why GPUs Matter: The Key to Scalable AI Without Coding

Artificial intelligence is everywhere — from AI art and video tools to chatbots and no-code apps. But why does it all work so fast — and scale to millions? The answer: GPUs.
Whether you’re a developer, founder, or no-code builder, understanding why GPUs matter can help you make better choices when running or deploying AI models in the cloud.
What Makes GPUs So Important for AI?
Unlike CPUs (Central Processing Units), which are optimized for sequential tasks, GPUs can handle thousands of operations in parallel. This makes them perfect for workloads like:
- Training large language models (LLMs) like LLaMA or Mistral
- Running real-time image or video generation
- Powering AI inference in production — fast, responsive outputs
Even when using no-code AI platforms, you’re still relying on GPU infrastructure in the background — that’s what powers the speed and scalability.
Unlike CPUs, which are optimized for sequential tasks, GPUs are built to process thousands of operations in parallel — the exact pattern AI workloads demand.
Let’s compare performance between a typical CPU and a high-end GPU like the NVIDIA H100, which powers many of Nebula Block’s offerings:
Metric | CPU | GPU (NVIDIA H100) |
|---|---|---|
Cores | 8–32 | 14,592 |
Memory Bandwidth | ~100 GB/s | 3,350 GB/s |
Best For | Sequential tasks | AI parallel workloads |
Cost per hour | $0.10–0.50 | $2–4 (but 10–50× faster) |
Modern AI models likemeta-llama/Llama-3-70B-Instructorstabilityai/stable-diffusion-xl-base-1.0require enormous memory bandwidth and parallel compute — something a CPU just can’t deliver efficiently
No-Code AI = Still Needs GPU Power
No-code AI tools like:
- Prompt-based model hosting (e.g., chatbot builders)
- AI-generated images or music
- Drag-and-drop LLM apps
...all depend on cloud GPU resources. Without GPUs, inference (i.e., when the AI generates a response) would be too slow and costly to scale.
Even small tasks — like turning text prompts into answers or images — require billions of matrix operations under the hood.
✅ Better GPU infra = lower latency + lower cost per run.
How Nebula Block Makes GPU-Powered AI Accessible
Full AI Infrastructure Included:
At Nebula Block, we provide cloud access to industry-leading GPUs like:
- GPU Instances for training and custom workloads
- Reserved instances with cost savings up to 40%
- Object Storage compatible with S3 for datasets and outputs
- Team collaboration tools for managing access and projects
- Dashboard for usage, billing, and scaling
Compared to big cloud platforms, Nebula Block’s effective GPU costs are up to 40–60% cheaper — making scalable AI more accessible than ever.
What makes Nebula Block different:
- Instant start: Serverless inference via API or simple GUI
- Pay-per-use: Billed by the second or token
- Zero DevOps: No Docker, infra setup, or backend engineering needed
- OpenAI-compatible APIs: Drop-in replacement for popular workflows
- S3-compatible object storage: Store models, datasets, and results
Example: Running Inference on Nebula Block (No DevOps Required)
Using Web UI:
- Go to Serverless Models
- Select model like LLaMA-3-70B
- Enter your prompt in the input box (e.g., “Explain how GPUs accelerate AI inference”)
- Enter — results appear instantly
- Optional: adjust output length, temperature in the right box
Using API:
- Select API tab:
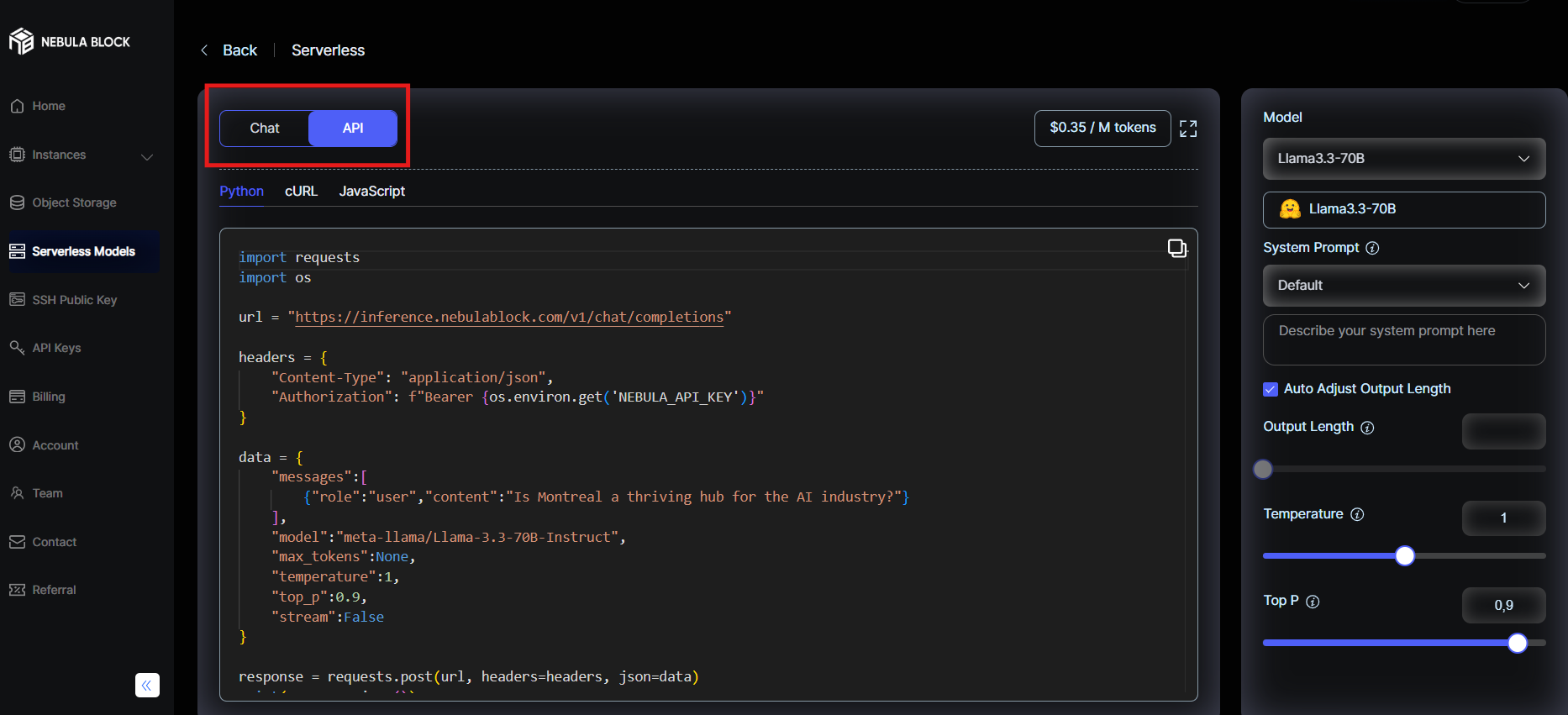
- Choose your language: Python, cURL, or JavaScript
- Copy and paste the pre-filled code sample. For example:
import requests
import os
url = "https://inference.nebulablock.com/v1/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {os.environ.get('NEBULA_API_KEY')}"
}
data = {
"messages":[
{"role":"user","content":"Explain how GPUs accelerate AI inference?"}
],
"model":"meta-llama/Llama-3.3-70B-Instruct",
"max_tokens":None,
"temperature":1,
"top_p":0.9,
"stream":False
}
response = requests.post(url, headers=headers, json=data)
print(response.json())Reminder: Replace NEBULA_API_KEY with your key here
No container setup. No server deployment. Just results.
The Engine Behind Modern AI
You don’t need to write code to use AI — but you do need the right compute power.
GPUs make it possible to run complex models fast, at scale, and affordably.
With Nebula Block, anyone can tap into high-performance GPU compute — whether you're a solo founder, ML team, or no-code builder.
No servers. No complexity. Just AI that works.
Next Steps
Sign up and explore now.
🔍 Learn more: Visit our blog and documents for more insights or schedule a demo to optimize your search solutions.
📬 Get in touch: Join our Discord community for help or Contact Us.
Stay Connected
💻 Website: nebulablock.com
📖 Docs: docs.nebulablock.com
🐦 Twitter: @nebulablockdata
🐙 GitHub: Nebula-Block-Data
🎮 Discord: Join our Discord
✍️ Blog: Read our Blog
📚 Medium: Follow on Medium
🔗 LinkedIn: Connect on LinkedIn
▶️ YouTube: Subscribe on YouTube