Unleash Next-Gen AI Power: RTX Pro™ 6000s and B200 Now Live on Nebula Block

The landscape of AI infrastructure is advancing rapidly — and Nebula Block is now equipped to meet the rising demands of researchers, developers, and AI-native companies. We're excited to announce the launch of NVIDIA RTX Pro™ 6000 and Blackwell B200 GPU instances on our platform, delivering unmatched performance for both experimental and production-scale AI.
RTX Pro™ 6000: Precision & Affordability for Daily AI Workloads
The RTX Pro™ 6000, built on NVIDIA’s professional-grade architecture, it offers high parallel compute performance, fast memory bandwidth, and generous VRAM to handle larger inputs and more complex models without compromise.

Key Technical Specs:
- Price per Hour: $1.49
- CUDA Cores: 24,064
- Tensor Cores: 5th Gen
- GPU Memory: 96 GB GDDR7 with error-correcting code (ECC)
- Memory Bandwidth: ~1.79 TB/s
- FP4 Throughput: 18 petaFLOPS
- vCPU: 7 cores
- RAM: 120 GB
- Disk: 1.46 TB SSD
✅ Ideal Use Cases:
- Fine-tuning open-source LLMs (LLaMA, Mistral, DeepSeek, etc.)
- Generating high-resolution images with Stable Diffusion XL
- AI-powered video editing and frame interpolation
- Building and testing AI prototypes at scale
- Training and inference for medium-to-large models
With 96 GB of VRAM and strong tensor throughput, the RTX Pro™ 6000 is ideal for developers and researchers who need professional performance at a developer-friendly price — all instantly available on Nebula Block without setup overhead.
B200 Blackwell: Ultimate Performance for Next-Gen AI
NVIDIA Blackwell™ B200 is the new gold standard for scalable AI infrastructure — built for large-scale training, multi-modal agents, and billion-parameter workloads.

Key Technical Specs:
- Price per Hour: $4.99/hr (single GPU)
- GPU Memory: 192 GB HBM3e
- Memory Bandwidth: 8 TB/s
- FP4 Throughput: 18 petaFLOPS
- vCPU: 20 cores
- RAM: 224 GB
- Disk: 2 TB SSD
- Ephemeral Storage: 4 TB
- NVLink: Enabled (multi-GPU support)
For the most demanding users, scale up to B200-NVLink 8-cluster at just $39.92/hr — enabling blazing-fast distributed training, minimal latency, and full Blackwell interconnect bandwidth.
Note: B200 is currently available exclusively in US regions.
Built for:
- Pretraining or fine-tuning GPT-class LLMs
- Multi-modal workflows (e.g., text+vision/audio agents)
- RAG pipelines at scale
- Reinforcement learning and simulation-heavy tasks
- AI startups needing enterprise-grade infrastructure without infra complexity.
Why It Matters
- Tailored Compute for Every Stage: From affordable RTX nodes for experimentation to ultra-high-end B200s for production.
- No Infrastructure Headaches: Spin up environments in seconds with PyTorch/CUDA compatibility out of the box.
- Global Deployment, Local Efficiency: Currently live in U.S. regions, Nebula Block ensures low-latency access to Blackwell power.
- Future-Proof Performance: GPU memory and FLOPS that meet the demands of tomorrow’s foundation models.
How to Get Started
To access the new RTX Pro™ 6000s and B200 instances, simply follow these steps:
- Log into Your Nebula Block Account:
- If you do not have an account, sign up at Nebula Block.
- Provision a New GPU Instance:
- Navigate to the "Instances" creation interface and select the B200 type along with the RTX Pro™ 6000s GPU option.
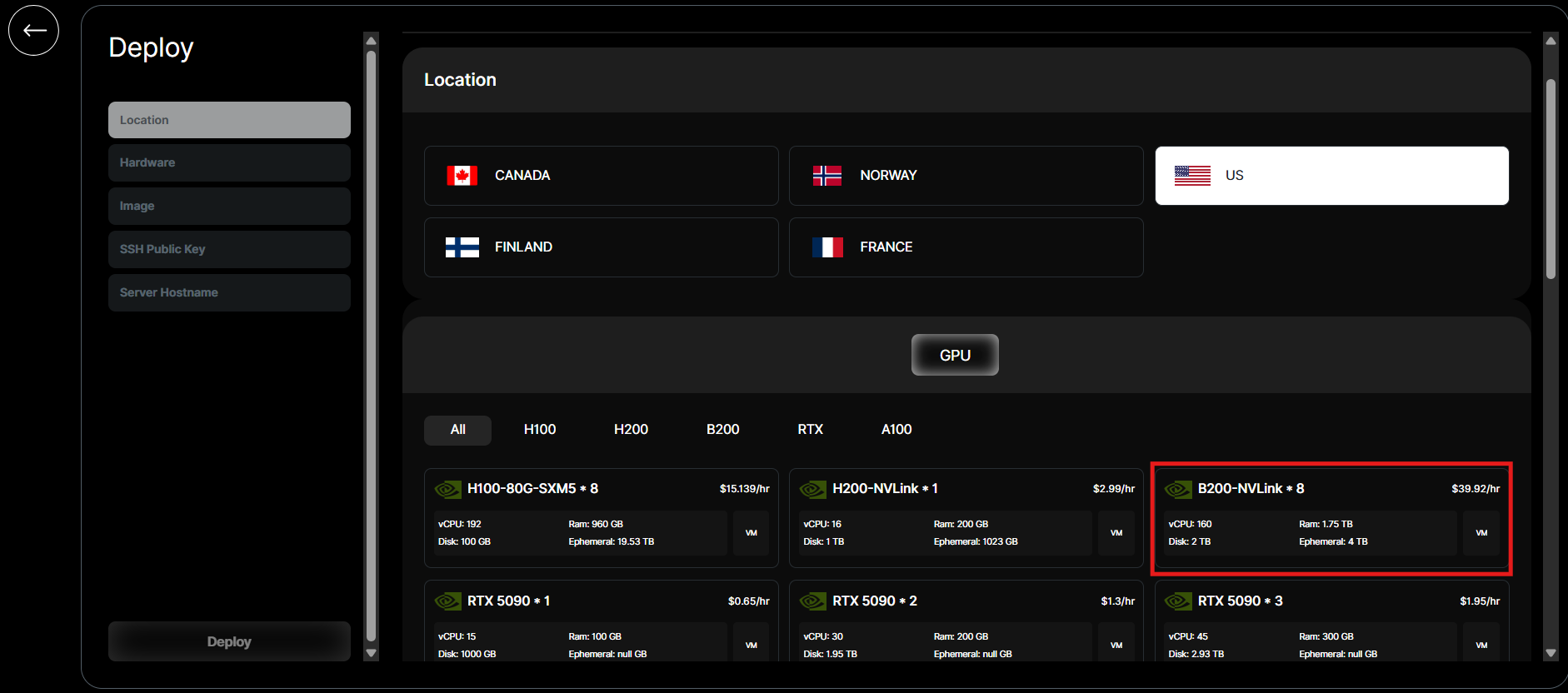
- Configure the instance according to your project’s requirements, including selecting the operating system and adding SSH keys for secure access.
For more details about SSH Key, visit this page
- Begin Driving Innovation:
- Once your instance is up and running, utilize the extensive resources and robust tooling available on Nebula Block to start building and experimenting with your AI projects.
💡Quick tip: Let our AI bot help you match the perfect GPU to your workload — just ask!
Conclusion
With the introduction of the RTX Pro™ 6000s and B200 instances on Nebula Block, users now have access to an exceptionally powerful infrastructure designed for the next generation of AI applications. Whether you are pushing the frontiers of research or developing practical AI solutions, these GPUs are tailored to meet the rigorous demands of modern workloads.
Next Steps
Sign up and explore now.
🔍 Learn more: Visit our blog and documents for more insights or schedule a demo to optimize your search solutions.
📬 Get in touch: Join our Discord community for help or Contact Us.
Stay Connected
💻 Website: nebulablock.com
📖 Docs: docs.nebulablock.com
🐦 Twitter: @nebulablockdata
🐙 GitHub: Nebula-Block-Data
🎮 Discord: Join our Discord
✍️ Blog: Read our Blog
📚 Medium: Follow on Medium
🔗 LinkedIn: Connect on LinkedIn
▶️ YouTube: Subscribe on YouTube