RTX 5090 vs 4090 vs Pro 6000: Gaming & Vision Tasks

As the GPU landscape evolves, choosing the right card depends less on raw specs and more on how well it handles real-world workloads. From high-resolution gaming to image generation, video processing, and multimodal AI, today's GPUs serve a wide range of demands that blur the line between consumer and professional use.
In this post, we break down the capabilities, pricing, and ideal applications of the RTX 4090, 5090, and Pro 6000—highlighting their performance on Nebula Block with a focus on gaming and vision-centric tasks.
Why It Matters
- Gamers and ML developers increasingly overlap—tools like LLaVA, ControlNet, and Stable Diffusion blur the lines between gaming rigs and AI workstations.
- Vision and multimodal AI models are GPU-hungry, but not all require H100s. RTX cards with large VRAM can offer excellent tradeoffs.
- If you're building pipelines for image/video generation, real-time segmentation, or diffusion models, understanding each GPU’s bandwidth, VRAM, and cost efficiency is critical.
GPU Overview & Specs
| GPU | VRAM / BW | FP32 TFLOPS | Power TDP | Key Advantage | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RTX 4090 | 24 GB / ~900 GB/s | ~83 | 450W | Cost-effective for short inference | |||||||||||||||||||||||||||||
| RTX 5090 | 32 GB / 1.8 TB/s | ~105 | 575W | Balanced performance & memory | |||||||||||||||||||||||||||||
| RTX PRO 6000 | 96 GB ECC / 1.8 TB/s | ~125 | ~600W | High VRAM + ECC for enterprise ML | |||||||||||||||||||||||||||||
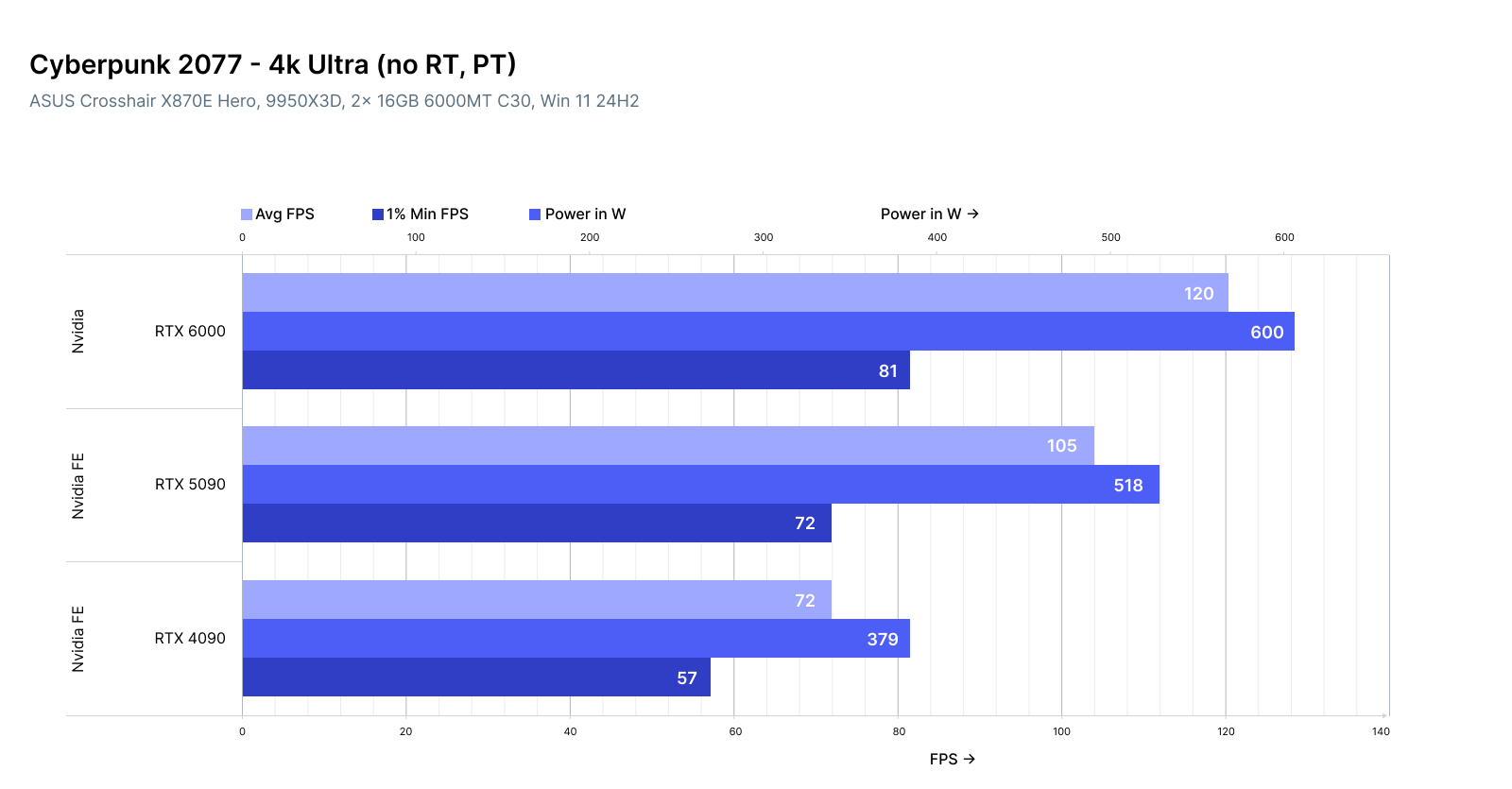
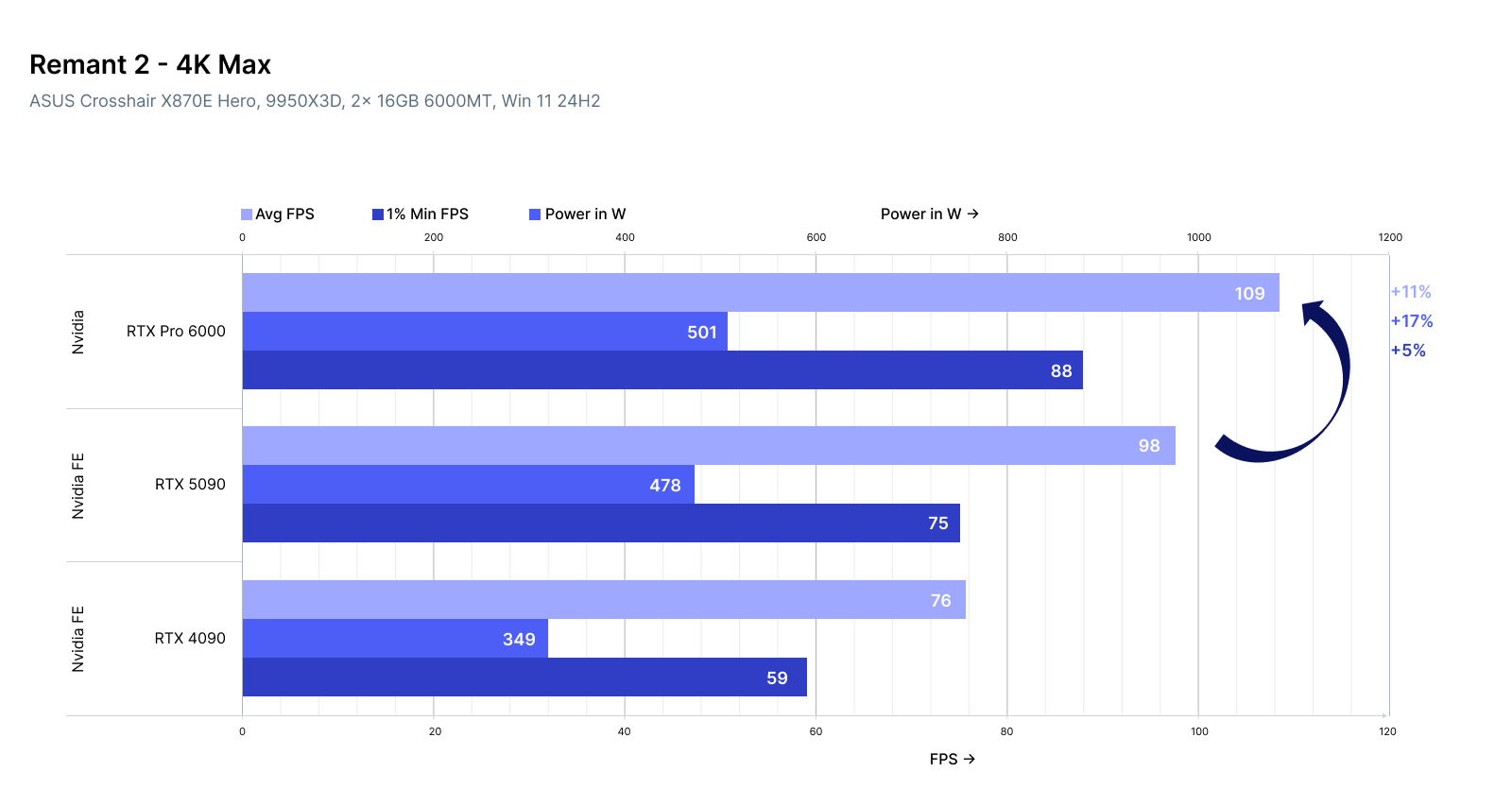
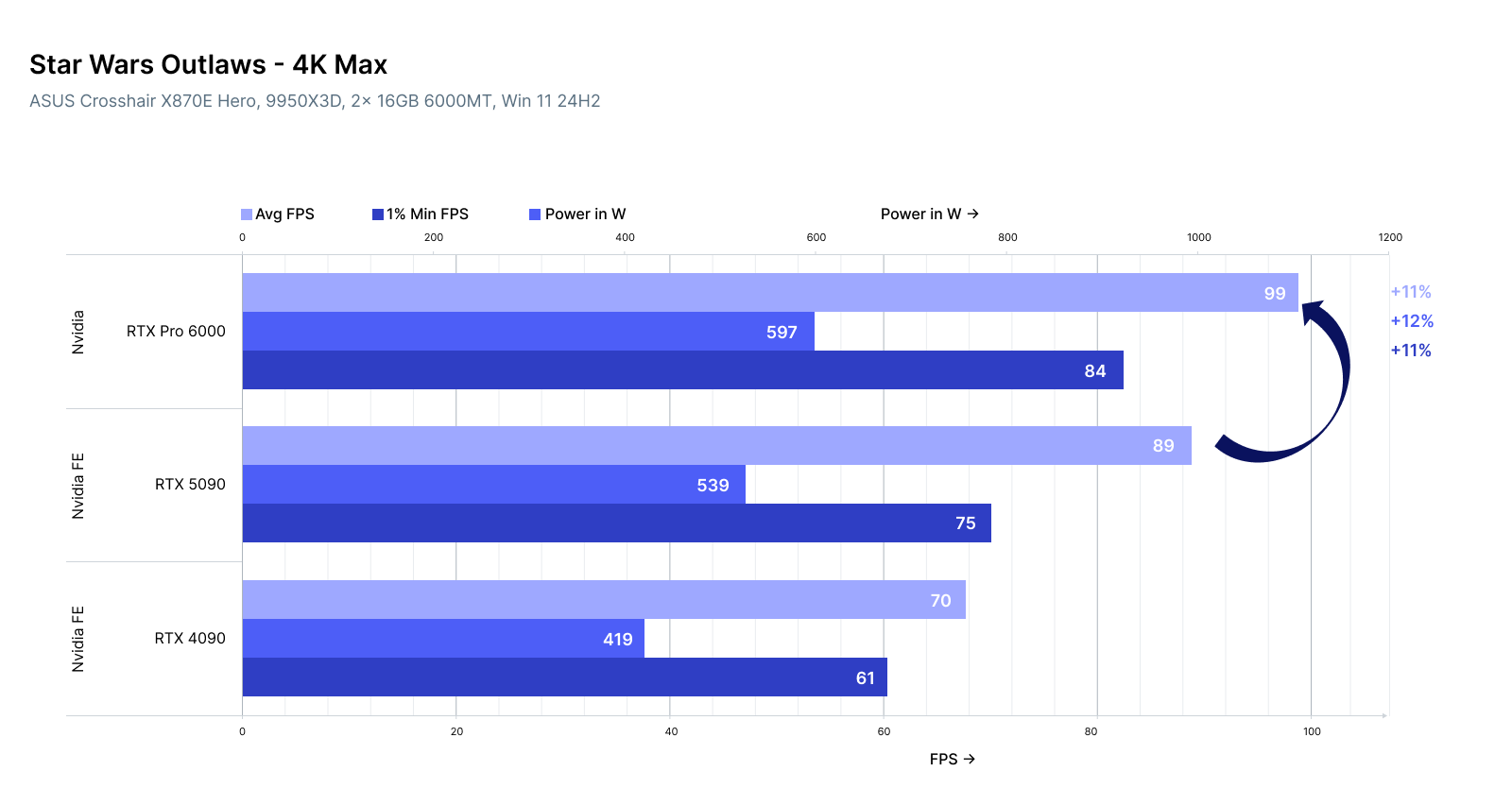
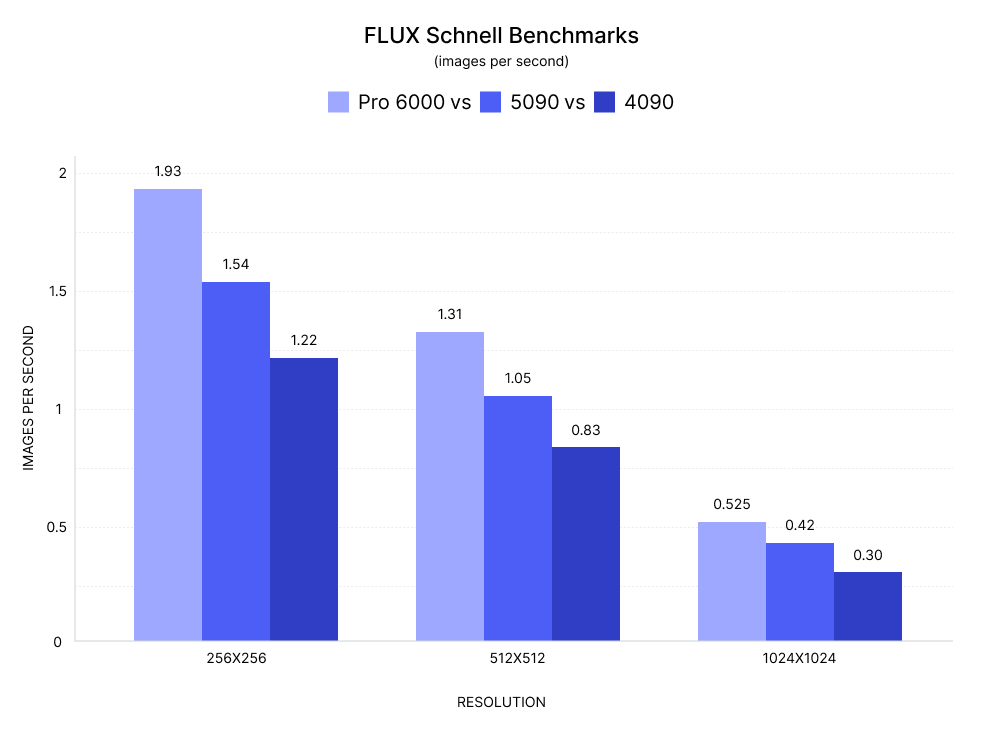
| Task | RTX 4090 | RTX 5090 | RTX Pro 6000 |
| LLaVA-1.6 (Image + Text) | ✅ Fast | ✅ Faster | ✅ Stable |
| ControlNet Inference (SDXL) | ✅ | ✅✅ | ✅✅✅ |
| Video-to-Text Embedding | ⚠️ Bottlenecks | ✅ | ✅✅✅ |
| Image-to-Image (img2img) | ✅ | ✅✅ | ✅✅✅ |
| Video Gen (Stable Video Diff) | ⚠️ VRAM limit | ✅ | ✅✅✅ |
5090 emerges as a hybrid king: powerful enough for heavy image workflows, and fast enough for real-time experiments.
Pro 6000 shines when you want stability + capacity—useful for long-running image pipelines, 3D render queues, or multi-modal agents processing large datasets.
When to Use Which GPU on Nebula Block
| Use Case | Best Choice |
| 4K+ gaming + fast prototyping | RTX 5090 |
| Real-time segmentation, LLaVA | RTX 5090 |
| Diffusion + ControlNet | Pro 6000 |
| Video-to-text, long vision loops | Pro 6000 |