Revolutionizing BERT Fine-tuning: How Nebula Block’s AI Infrastructure Transforms Large Model Development

The landscape of natural language processing has been fundamentally transformed by BERT (Bidirectional Encoder Representations from Transformers) and subsequent large language models. As organizations increasingly adopt these powerful models for specialized applications, the challenge of efficient fine-tuning has become paramount.
Nebula Block, with over seven years of expertise in high-performance GPU hosting, is addressing this critical need with cutting-edge infrastructure designed specifically for AI workloads.
The Growing Demand for BERT Fine-tuning
BERT’s revolutionary approach to understanding context through bidirectional training has made it the foundation for countless NLP applications.
According to recent research from Hugging Face, fine-tuning BERT variants remains one of the most common approaches for domain-specific language tasks, with over 4,000 BERT-based models currently hosted on their platform (Hugging Face Model Hub Statistics). However, the computational requirements for effective fine-tuning continue to challenge organizations seeking to implement these models at scale.
Fine-tuning large models like BERT-Large, with its 340 million parameters, or newer variants like RoBERTa and DeBERTa, requires substantial computational resources and specialized infrastructure. Traditional cloud solutions often present cost barriers that limit experimentation and deployment.
Nebula Block’s Competitive Advantage in Model Fine-tuning
Nebula Block’s decentralized platform addresses these challenges through a comprehensive suite of AI-optimized services. The platform’s dedicated endpoints provide reserved GPU-powered infrastructure specifically designed for fine-tuning custom models, utilizing cutting-edge hardware including RTX 5090, H100, and A100 GPUs GPUs optimized for AI training workloads.
The cost advantage is significant: Nebula Block offers capabilities at 50% to 80% less expense than major cloud providers without compromising performance.
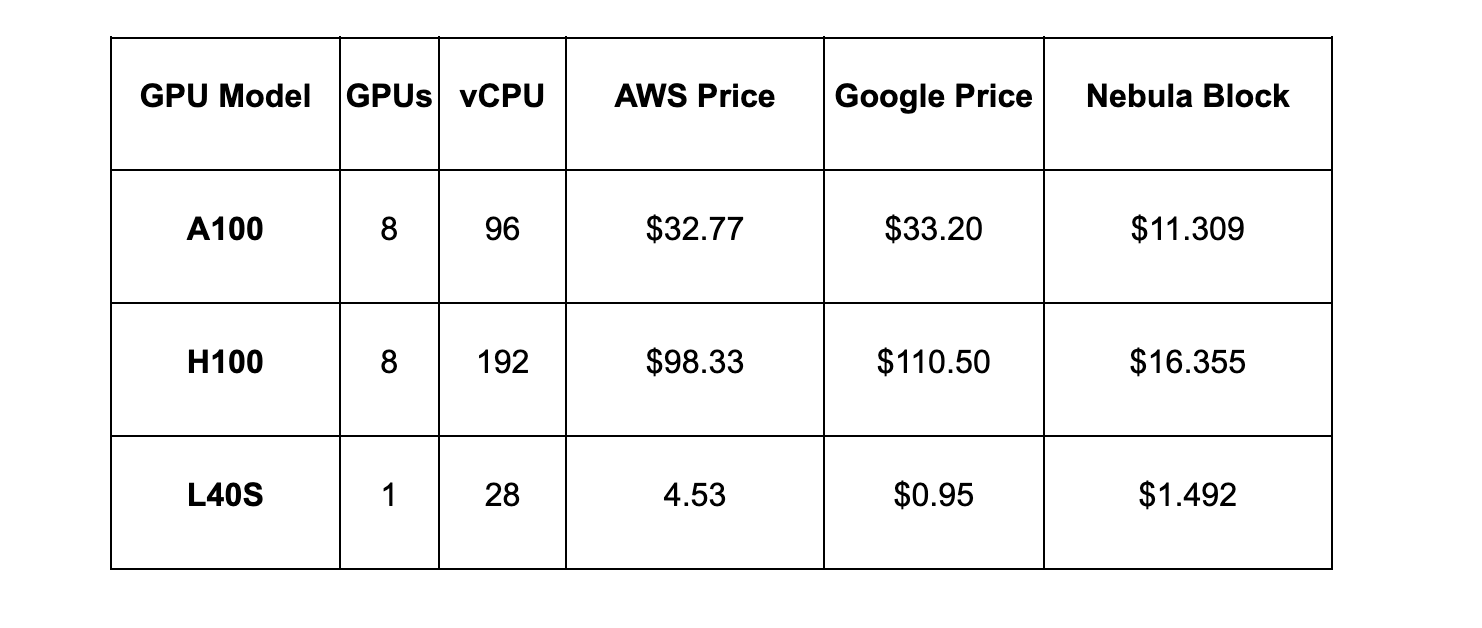
This cost efficiency is particularly crucial for BERT fine-tuning projects, which often require extensive hyperparameter experimentation and multiple training runs to achieve optimal results.
Technical Infrastructure Optimized for Large Model Training
Nebula Block’s infrastructure is purpose-built for the demands of modern AI development. The platform provides fully customizable computing environments preloaded with critical AI frameworks including PyTorch, HuggingFace Transformers, FlashAttention, and Fully Sharded Data Parallel (FSDP) — all essential components for efficient BERT fine-tuning workflows.
The integration of FlashAttention is particularly noteworthy, as this optimization technique can reduce memory usage by up to 50% during transformer training while maintaining mathematical equivalence to standard attention mechanisms. According to Stanford’s original FlashAttention research, this approach enables training of significantly larger models or larger batch sizes on the same hardware (FlashAttention: Fast and Memory-Efficient Exact Attention).
Seamless Integration with Modern AI Workflows
Nebula Block’s serverless endpoints provide instant access to popular foundation models, including Meta’s LLaMA series and DeepSeek models, through managed APIs with effortless scaling. This capability allows researchers and developers to compare their fine-tuned BERT models against state-of-the-art alternatives, facilitating more informed model selection decisions.

The platform’s S3-compatible object storage ensures secure and scalable management of training datasets and model checkpoints — critical components of any serious fine-tuning operation. With full SSH access and compatibility with all leading open-source AI models, teams can implement custom training pipelines while maintaining the flexibility to adapt to evolving requirements.

Empowering Canadian AI Innovation
As a spin-out of Montreal-based Nebula AI, Nebula Block is uniquely positioned to serve Canada’s AI ecosystem. The platform addresses Canada’s documented AI compute shortfall while providing sovereign cloud capabilities that keep sensitive research and development within Canadian borders.
This sovereign approach is increasingly important as organizations recognize the strategic value of maintaining control over their AI infrastructure and data. Nebula Block’s Canadian foundation ensures compliance with local data governance requirements while providing the performance and cost efficiency needed for competitive AI development.
The Future of Accessible AI Infrastructure
Nebula Block’s vision extends beyond traditional cloud computing to create an ecosystem where “building AI agents is as simple as making an app.” This democratization of AI infrastructure is particularly relevant for BERT fine-tuning, where the barrier to entry has historically been high due to infrastructure complexity and costs.
The platform’s combination of cutting-edge hardware, optimized software environments, and cost-effective pricing creates new possibilities for organizations of all sizes to leverage the power of fine-tuned language models. Whether developing specialized NLP applications, conducting academic research, or building commercial AI products, Nebula Block provides the foundation for innovation.
As the AI landscape continues to evolve, Nebula Block will play an increasingly critical role in ensuring that advanced capabilities remain accessible to the broader developer community. By reducing the infrastructure burden associated with model fine-tuning, Nebula Block enables teams to focus on what matters most: creating intelligent applications that solve real-world problems.
🔗 Start building today: Explore Nebula Block.
Stay Connected
💻 Website: nebulablock.com
📖 Docs: docs.nebulablock.com
🐦 Twitter: @nebulablockdata
🐙 GitHub: Nebula-Block-Data
🎮 Discord: Join our Discord
✍️ Blog: Read our Blog
📚 Medium: Follow on Medium
🔗 LinkedIn: Connect on LinkedIn
▶️ YouTube: Subscribe on YouTube