Qwen2.5-Omni-7B: Versatile Multimodal AI for Next-Gen Applications

The world of AI continues to evolve at lightning speed, and with the release of Qwen2.5-Omni-7B, we’re witnessing a leap toward seamless multimodal interaction. Developed by the team behind Qwen at Alibaba Cloud, this 7-billion-parameter model isn't just another large language model (LLM)—it's a transformative step in bridging the gap between text and speech.
At NebulaBlock, we’re always excited to showcase models that push the boundaries of what’s possible. In this post, we’ll introduce Qwen2.5-Omni-7B, dive into what makes it technically remarkable, and explore real-world applications with broad, practical relevance across various sectors.
What Is Qwen2.5-Omni-7B?
Qwen2.5-Omni-7B is a compact, end-to-end multimodal model built to understand inputs across text, images, audio, and video, while generating both text and natural speech responses in real time. It combines the power of textual reasoning with fluid, natural voice output, making it well-suited for interactive applications such as AI agents, real-time translation systems, and educational tutors.
Omni employs a dual-architecture design, called the Thinker-Talker framework:
- Thinker: This module is responsible for performing the core task of text comprehension and generation. It handles the reasoning, planning, and semantic understanding—basically, it thinks.
- Talker: This module receives high-level semantic representations from the Thinker and converts them into streaming speech tokens. The result: speech output that is both responsive and contextually rich.
This separation of concerns leads to high performance in both domains without compromising one for the other. It's an elegant solution to the classic problem of managing multiple modalities within a single model, as shown by their benchmarks and performance results (for those who are curious, see their paper here)
Technical Highlights
- Size: 7B parameters, striking a balance between performance and efficiency
- Architecture: Dual-module Thinker-Talker framework
- Modalities: Handles text, images, audio, and video, and outputs text and natural speech responses in a streaming manner
- Applications: Dialogue systems, voice agents, accessibility tools, education, content creation, customer service, and more
- Deployment Flexibility: Open source allows Omni to be accessible to the public
Why This Model Matters
Speech is a highly natural medium of communication for humans, and so multimodal models supporting speech open up a huge range of possibilities. It can also help speech specific users, such as individuals with disabilities, young learners, or users with occupied hands. Qwen2.5-Omni addresses this need head-on, offering a unified solution that can both understand and speak at low computational cost.
The Thinker-Talker framework also opens the door to modular experimentation. Developers can enhance or customize either the Thinker or Talker independently, enabling targeted improvements or domain-specific adaptations.
Applications
Qwen2.5-Omni-7B's impressive performance can help build smarter, more responsive, and more human-centric applications. With its ability to understand text, image, audio, and video, this model is ideally suited for projects that rely on multimodal interaction.
Some high-impact application areas include:
- Voice Assistants: Build conversational agents that can speak naturally and respond to both spoken and written inputs.
- Educational Tools: Deliver real-time tutoring experiences that combine visual aids, interactive text, and spoken feedback.
- Accessibility Interfaces: Empower users with visual or cognitive impairments through responsive speech-based interaction.
- Customer Experience: Enhance help desks and chatbots with voice output that’s informative and human-like.
- Creative Tools: Design AI-powered storytellers, podcast narrators, and content generators that speak fluently and engage users in new ways.
Some of these ideas might sound ambitious or out of reach. You might be wondering—how do you even begin integrating a model this advanced? Doesn’t it take a whole AI team to make it work? Not at all. With NebulaBlock’s serverless inference, bringing powerful models like Qwen2.5-Omni-7B into your project is straightforward and accessible. Let’s walk through an example of how it works in practice.
Example Integration Workflow: A Multilingual Interactive Story App
Suppose you're building a mobile app that delivers personalized interactive stories for children across different languages. Here's how Qwen2.5-Omni-7B could fit seamlessly into your backend:
- User Input: The user (eg. a parent) starts the storytelling workflow in your application, providing text or audio to guide the story.
- Thinker Phase: Your application passes this data to the Omni model in a couple lines in your program through a simple API request. Its Thinker module will analyze context, understand the user's intent, and generates the next part of the story in text form.
- Talker Phase: The generated text is passed to the Talker module, which turns it into spoken audio.
- Streaming Output: The speech is streamed back to the app in real time, giving the child an immersive, conversational storytelling experience.
- Serverless Scaling: Using our platform, this pipeline runs through serverless endpoints—no infrastructure to manage, no servers to scale. You focus on your app; we handle the AI inference.
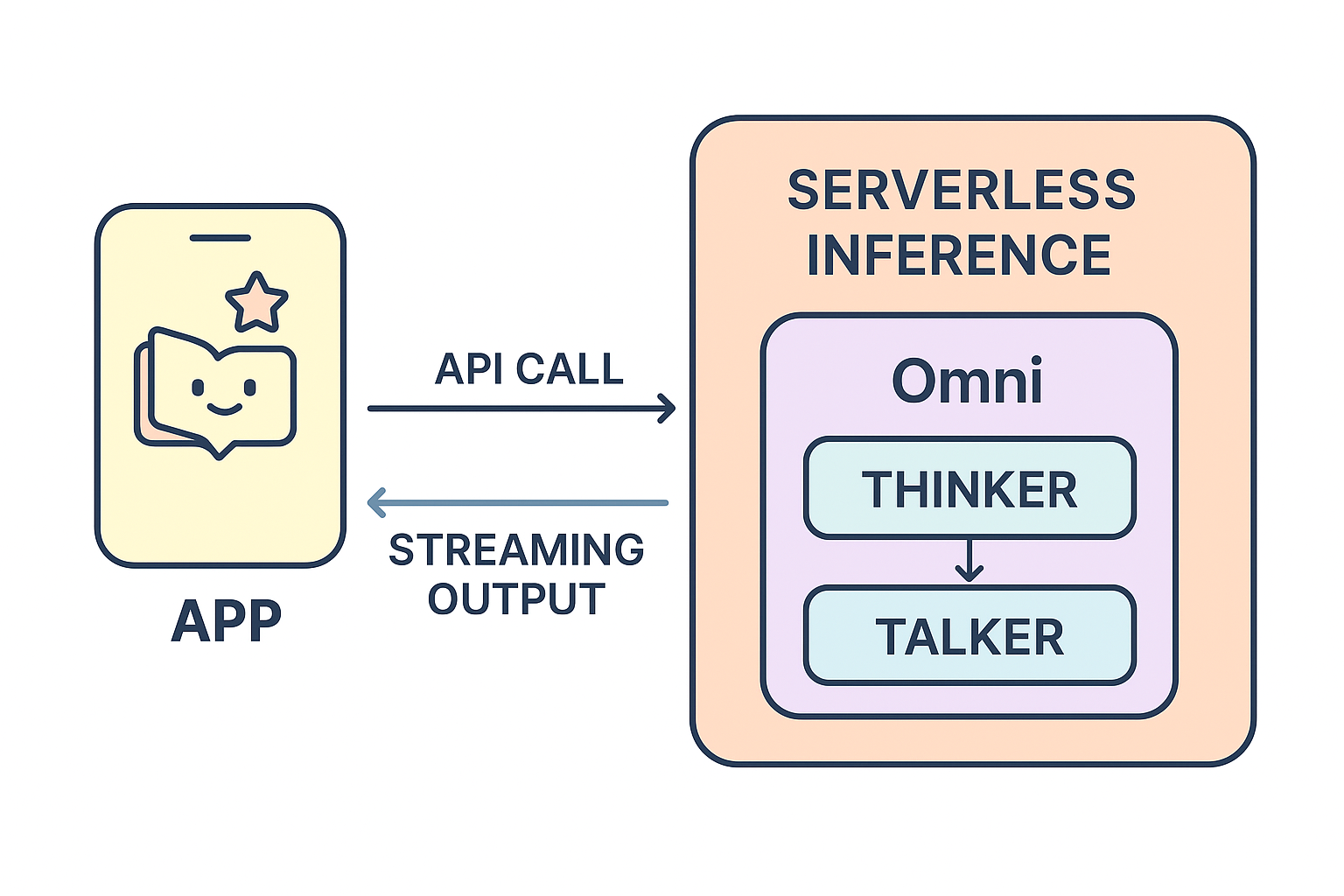
This is just one of many workflows our Omni inference can make possible. Whether you’re building for education, entertainment, accessibility, or enterprise productivity, we can give you the model as a plug-and-play intelligence layer—available as an API.
Have an exciting application that could benefit from Omni?
If you're inspired by the potential of Qwen2.5-Omni-7B and want to build AI-driven voice products, language tutors, interactive storytellers, or even tools for the visually impaired—we’re here to help. At NebulaBlock, we’re constantly launching serverless endpoints to make integrations like this easy and scalable. While our API support for Qwen2.5-Omni-7B isn’t public yet, we’re eager to partner with teams that want to explore what’s possible today.
Have a use case in mind? Get in touch with our team at NebulaBlock here to find how we can help you integrate this cutting-edge model into your project!
Click here to sign up and receive $10 welcome credit!
Stay Connected
💻 Website: nebulablock.com
📖 Docs: docs.nebulablock.com
🐦 Twitter: @nebulablockdata
🐙 GitHub: Nebula-Block-Data
🎮 Discord: Join our Discord
✍️ Blog: Read our Blog
📚 Medium: Follow on Medium
🔗 LinkedIn: Connect on LinkedIn
▶️ YouTube: Subscribe on YouTube