As the GPU landscape evolves, choosing the right card depends less on raw specs and more on how well it handles real-world workloads. From high-resolution gaming to image generation, video processing, and multimodal AI, today's GPUs serve a wide range of demands that blur the line between consumer and professional use.
In this post, we break down the capabilities, pricing, and ideal applications of the RTX 4090, 5090, and Pro 6000—highlighting their performance on Nebula Block with a focus on gaming and vision-centric tasks.
Why It Matters
Gamers and ML developers increasingly overlap—tools like LLaVA, ControlNet, and Stable Diffusion blur the lines between gaming rigs and AI workstations.
Vision and multimodal AI models are GPU-hungry, but not all require H100s. RTX cards with large VRAM can offer excellent tradeoffs.
If you're building pipelines for image/video generation, real-time segmentation, or diffusion models, understanding each GPU’s bandwidth, VRAM, and cost efficiency is critical.
GPU Overview & Specs
GPU
VRAM / BW
FP32 TFLOPS
Power TDP
Key Advantage
RTX 4090
24 GB / ~900 GB/s
~83
450W
Cost-effective for short inference
RTX 5090
32 GB / 1.8 TB/s
~105
575W
Balanced performance & memory
RTX PRO 6000
96 GB ECC / 1.8 TB/s
~125
~600W
High VRAM + ECC for enterprise ML
Gaming & Vision Benchmarks
Gaming & Graphics Edge Cases
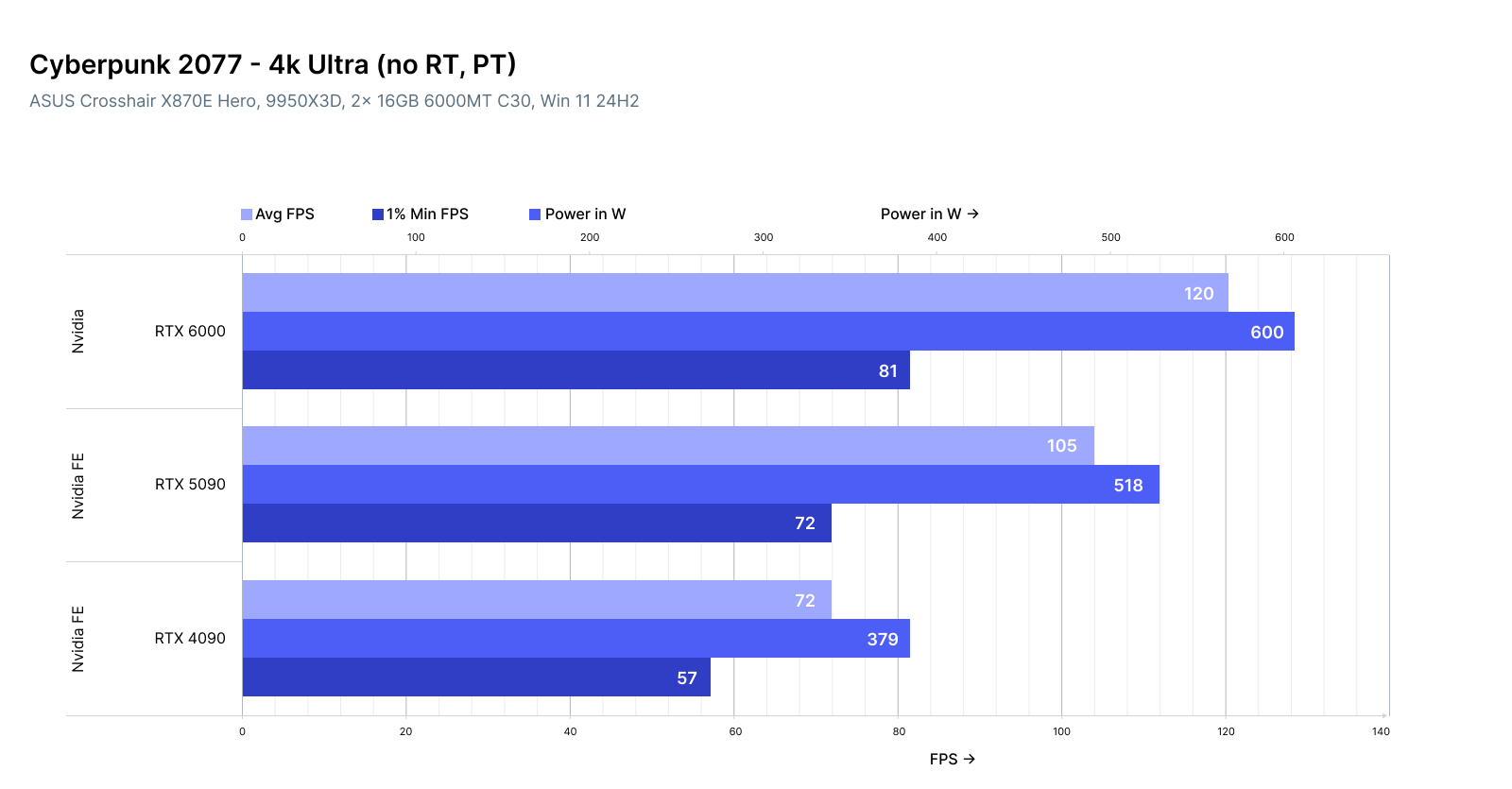
Based on tests from GameGPU, the RTX Pro 6000 excels in 4K gaming:
Cyberpunk 2077 (4K, No RT):
RTX Pro 6000: 120 FPS / 81 FPS 1% Low / 599W
RTX 5090: 105 FPS / 72 FPS / 518W
RTX 4090: 72 FPS / 57 FPS / 379W
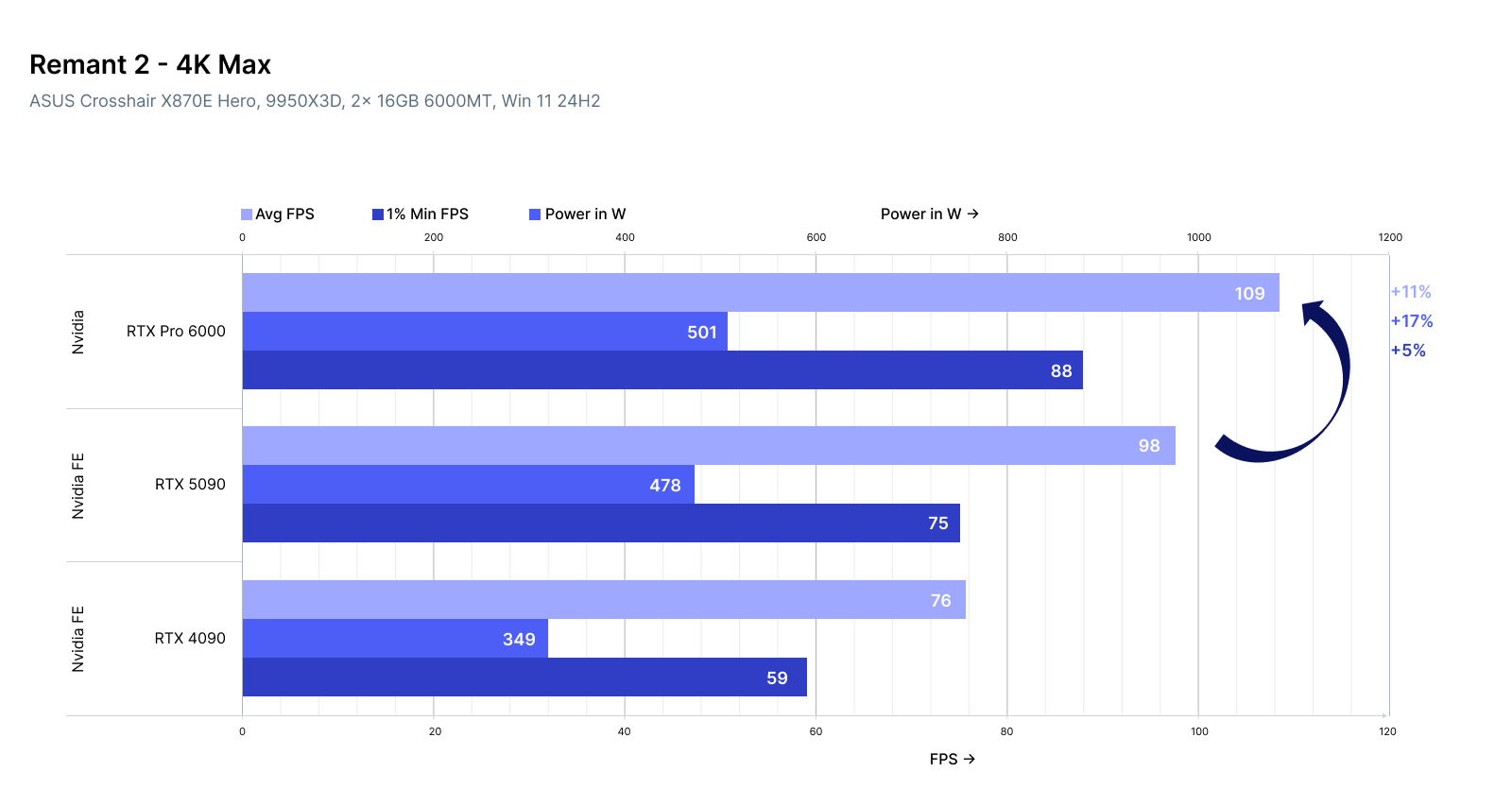
Remnant 2 (4K, Max):
RTX Pro 6000: 109 FPS / 88 FPS / 581W
RTX 5090: 98 FPS / 75 FPS / 476W
RTX 4090: 76 FPS / 59 FPS / 349W
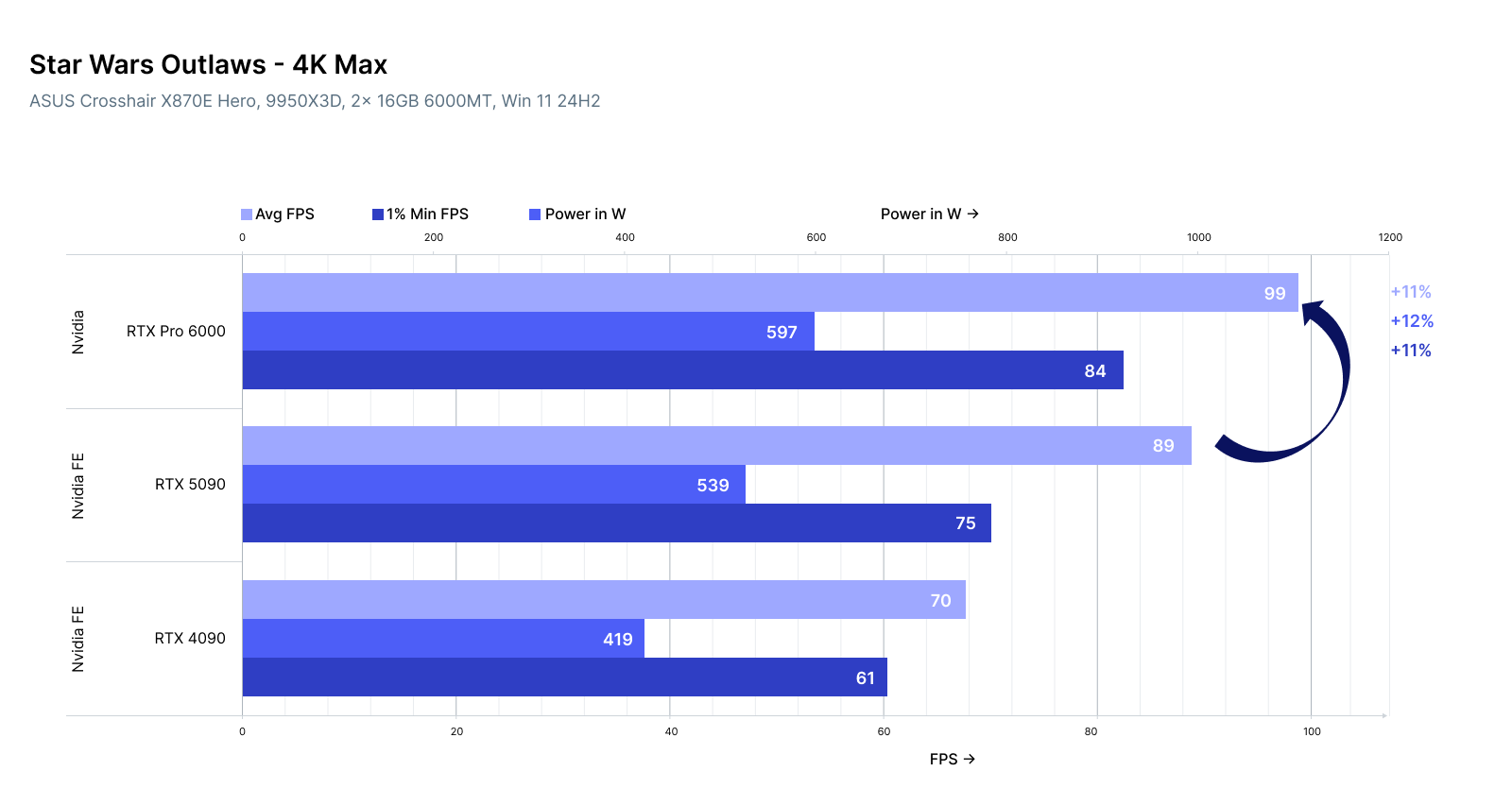
Star Wars Outlaws (4K, Max):
RTX Pro 6000: 99 FPS / 84 FPS / 597W
RTX 5090: 89 FPS / 75 FPS / 539W
RTX 4090: 70 FPS / 61 FPS / 419W
The RTX Pro 6000 is 11-14% faster than the 5090 but consumes 15% more power, using a GB202 core with 24,064 CUDA cores and 96GB GDDR7. However, it suffers from loud coil whine and aggressive fan noise.
For 3D rendering, the 5090 outperforms the 4090 by 12-50% in 4K benchmarks, while the Pro 6000 edges out the 5090 by 10-15% in GPU-intensive games like Cyberpunk 2077.
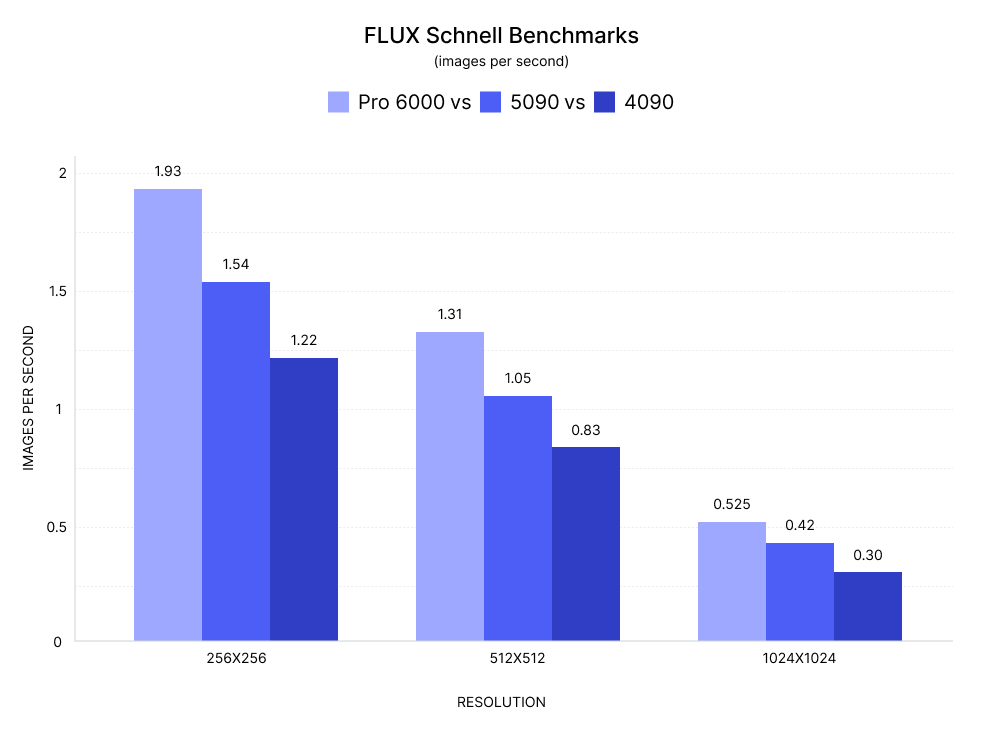
Visual benchmark: FLUX Schnell
The RTX 5090 consistently outperforms the 4090 at all tested resolutions, and closely trails the Pro 6000—especially in midrange workloads:
At lower resolutions (e.g., 256x256), the gap between GPUs is narrower due to lower memory pressure and shared reliance on FP8 + 4-step inference. But as resolution increases, the RTX 5090's Blackwell architecture and 32GB VRAM give it a clear advantage over the 4090—delivering up to 40% faster image generation at 1024x1024.
Task
RTX 4090
RTX 5090
RTX Pro 6000
LLaVA-1.6 (Image + Text)
✅ Fast
✅ Faster
✅ Stable
ControlNet Inference (SDXL)
✅
✅✅
✅✅✅
Video-to-Text Embedding
⚠️ Bottlenecks
✅
✅✅✅
Image-to-Image (img2img)
✅
✅✅
✅✅✅
Video Gen (Stable Video Diff)
⚠️ VRAM limit
✅
✅✅✅
5090 emerges as a hybrid king: powerful enough for heavy image workflows, and fast enough for real-time experiments.
Pro 6000 shines when you want stability + capacity—useful for long-running image pipelines, 3D render queues, or multi-modal agents processing large datasets.
When to Use Which GPU on Nebula Block
Use Case
Best Choice
4K+ gaming + fast prototyping
RTX 5090
Real-time segmentation, LLaVA
RTX 5090
Diffusion + ControlNet
Pro 6000
Video-to-text, long vision loops
Pro 6000
All the GPUs mentioned above—RTX 5090, Pro 6000, 4090—are available on Nebula Block, Canada’s first sovereign AI cloud. It offers both on-demand and reserved GPU instances, spanning enterprise-class accelerators for cost-effective experimentation.
With infrastructure across Canada and global latency optimization, you get fast, compliant access wherever you are.
Explore GPU instances, or try free endpoints like DeepSeek V3 and R1—ready to go, no deployment needed.
Nebula Block Advantage
Nebula Block offers flexible deployment for these GPUs:
GPU VMs: Rent virtual or bare-metal machines with RTX 4090, 5090, Pro 6000 and more.
Serverless Inference: Scale workloads without infrastructure management.
S3-compatible storage: Perfect for models, datasets, and logs.
Container-ready environments: Instantly deploy Hugging Face or OpenAI-compatible models.
Data Privacy by Design: Your models and data are isolated per instance—no shared memory or persistent containers by default.
Conclusion
RTX 4090: Cost-effective choice for short AI tasks, image generation, and high-end gaming.
RTX 5090: Well-balanced upgrade for scaling LLMs, multimodal models, or 4K gaming under heavier loads.
RTX Pro 6000: Built for enterprise-grade ML, stable long runs, and demanding visual workloads—with gaming performance to match.
On Nebula Block, rent the perfect GPU for your gaming or your work needs. Explore our platform to match your next deployment with the ideal compute layer.