Per-Second Billing on GPUs: The Hidden Superpower for AI Teams

In AI, compute is everything—and every second of GPU time matters.
Whether you're training models, running inference, or processing massive datasets, today’s AI workloads demand precision and flexibility. Yet most cloud providers still rely on outdated billing systems, rounding GPU usage up to the nearest hour—or worse, charging by the month.
That’s where Nebula Block stands apart.
With per-second billing, AI teams gain unmatched control over compute usage and cost. No overpayment. No lock-in. Just pure GPU performance, when you need it.
⏳ Why Hourly Billing Falls Short
Traditional billing models were built for web servers, not modern AI. Here’s what happens when your GPU time gets rounded up:
- Wasted credits and inflated costs for short tasks
- Overpayment during idle time (e.g., data loading, validation, queuing)
- Rigid contracts that block experimentation and iteration
For fast-moving AI teams, this isn’t just inefficient—it’s restrictive.
Nebula Block’s Per-Second Billing Advantage
With Nebula Block, you're only billed for the exact seconds your GPU is running. Whether you're fine-tuning on an H100 for 30 seconds or training across 4 GPUs for 15 minutes, you only pay for what you use.
Powered by a Transparent Credit System:
- Top up easily via Billing Portal
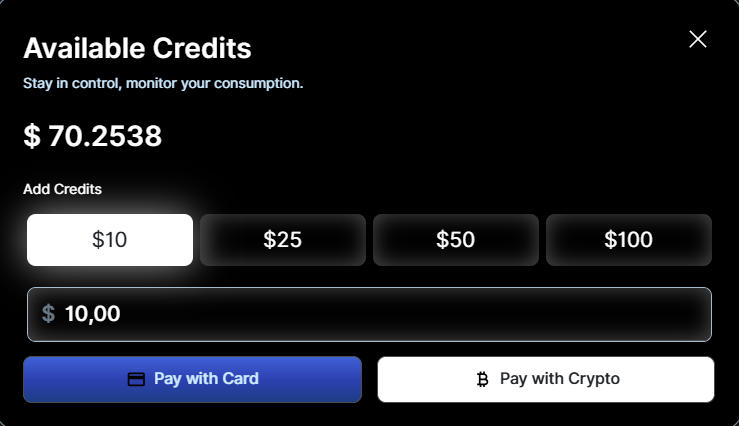
You can choose to deposit using a Card or Crypto, with Phantom wallet supported for crypto payments.
- Use credits across all instance types (A100, H100, H200, 5090 Pro…)
- Monitor usage in real-time
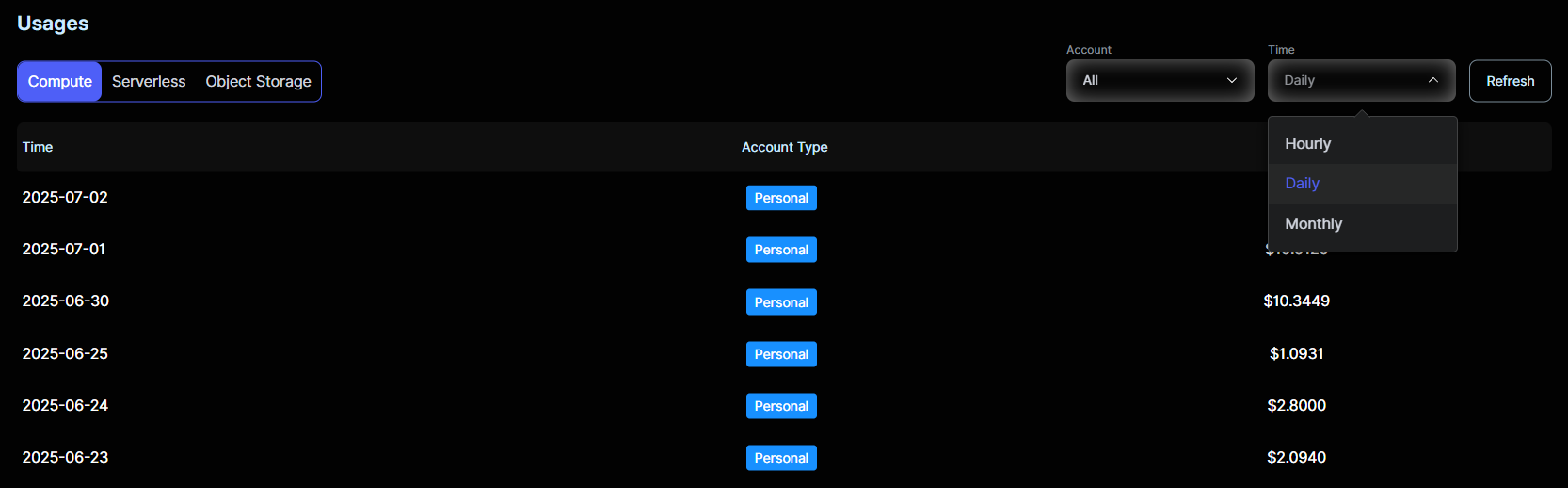
- Set auto-reload thresholds to avoid disruptions
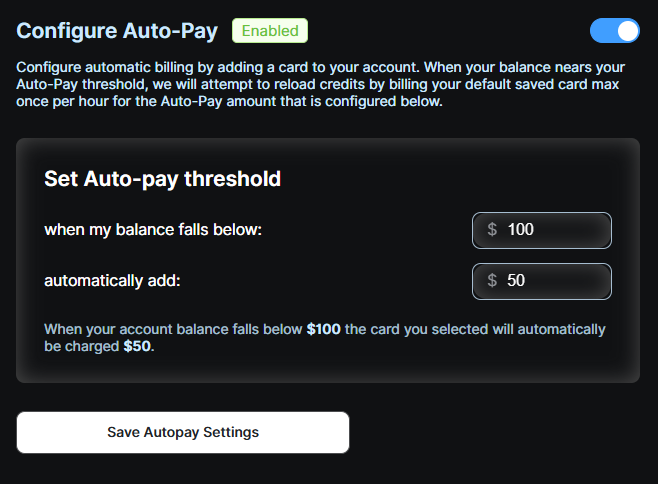
It’s usage-based billing, done right.
Why It Matters for AI Teams
Per-second billing doesn’t just save money—it enables better engineering.
✅ Burst-Ready Workloads
Train overnight, run inference in minutes, or scale up for peak demand. Pay only for active usage.
✅ Faster Experimentation
Try edge cases, launch quick tests, validate data flows—without worrying about hourly minimums.
✅ On-Demand Scalability
Spin up clusters for large-scale training. Shut them down instantly when done. No long-term commitment required.
✅ Predictable Budgets
Set credit reload amounts and thresholds. Use automation (API/CLI) to control spend and avoid surprises.
💡 Tip: Nebula Block supports Auto-Pay and programmatic billing alerts to keep your workflows uninterrupted.
Real-World Impact
An AI team processes a dataset in 15 minutes, then runs inference for 5. That’s 1,200 seconds total. Instead of getting billed for 2 hours, they pay only for 20 minutes. The result? Up to 80% savings on short or iterative tasks—freeing up budget for more compute or model experimentation.
For large projects, like training 70B+ parameter models, per-second billing enables cost-aware scaling. You can reduce GPU usage during validation or debugging and reinvest those saved credits into actual training time.
Use Case Scenarios
- Research Labs: Run multi-stage experiments across models and datasets without financial overhead.
- Startups & Builders: Prototype MVPs without committing to long-term GPU costs. Scale compute as you grow.
- Enterprise AI Ops: Dynamically scale compute based on workflow stages—integrate with DevOps pipelines.
- Academia & Hackathons: Train advanced models on a student budget—pay for seconds, not hours.
Bonus: Pay-as-you-Go Meets Automation
With Nebula Block’s REST API and CLI tools, you can:
- Launch/terminate GPU instances in minutes.
- Track billing programmatically.
- Set thresholds to alert or auto-reload when low on credits.
Perfect for agents, LLM deployments, multi-stage pipelines, or cloud-native ML workflows.
Why It Works in 2025
AI workflows in 2025 are iterative, automated, and unpredictable. You don’t need a static server for a month—you need GPU bursts that last 45 seconds or 12 minutes.
Nebula Block’s per-second billing reflects this reality:
- More Iteration → pay only for the runs you launch
- Dynamic Scaling → GPU demand shifts hourly
- Smarter Spending → budgets stretch further with granularity
Try it yourself
No GPU? No problem.
Start building and experience the freedom of per-second billing.
Scale when you're ready—just $10 unlocks access to premium GPUs (H100, H200, RTX 5090 Pro, and more).
Sign up and explore now.
🔍 Learn more: Visit our blog and documents for more insights or schedule a demo to optimize your search solutions.
📬 Get in touch: Join our Discord community for help or Contact Us.
Stay Connected
💻 Website: nebulablock.com
📖 Docs: docs.nebulablock.com
🐦 Twitter: @nebulablockdata
🐙 GitHub: Nebula-Block-Data
🎮 Discord: Join our Discord
✍️ Blog: Read our Blog
📚 Medium: Follow on Medium
🔗 LinkedIn: Connect on LinkedIn
▶️ YouTube: Subscribe on YouTube