Optimizing Nebula Block’s Embedding API for High-Volume NLP Applications

Introduction: Scaling NLP with Nebula Block
High-volume Natural Language Processing (NLP) applications, such as semantic search or real-time chatbots, demand fast, scalable embedding generation. Nebula Block’s Embedding API, powered by NVIDIA GPUs and serverless architecture, delivers up to 30% cost savings while handling millions of requests daily. This guide explores how to optimize the API for performance in high-throughput NLP tasks, ensuring low latency and cost efficiency.
Why Optimize the Embedding API?
Embeddings transform text into vector representations for tasks like similarity detection and clustering. In high-volume scenarios, unoptimized APIs can lead to bottlenecks, high costs, and latency spikes. Nebula Block’s platform, with H100/A100 GPUs across 100+ data centers, supports models like sentence-transformers/all-MiniLM-L6-v2 via vLLM for efficient inference. Optimizing the API helps scale your applications by reducing processing time and cost per request.
Optimization Strategies
Follow these steps to maximize Nebula Block’s Embedding API performance for high-volume NLP workloads.
1. Deploy a GPU Instance
Navigate to Nebula Block and sign up. In the portal, select “Instances” and deploy an NVIDIA H100 (80GB vRAM) for high-throughput embedding tasks, requiring ~12GB for all-MiniLM-L6-v2 in float16. Set:
- Instance Type: H100-80GB ($3.22/hour, 18% less than AWS’s $3.93).
- Region: Closest data center (e.g., US).Click “Deploy” (~2 minutes). This ensures dedicated compute power.

2. Configure the Embedding API
In the “Serverless” tab, create an endpoint with sentence-transformers/all-MiniLM-L6-v2 from Hugging Face, integrated with vLLM. Link the H100 instance and configure:
- Minimum Workers: 2 (scales to 0 when idle).
- Maximum Workers: 8 (for peak loads).
- Batch Size: 32 (adjust per request volume).Batching reduces per-request overhead, cutting latency by 40% for 10,000+ requests/second.
3. Enable Tensor Parallelism
For large-scale workloads, enable tensor parallelism to distribute embedding model layers across multiple GPUs. In the portal, under “Advanced Settings”, select “Tensor Parallelism” and set:
- GPU Count: 2–4 H100s.
- Embedding Layer: Use VocabParallelEmbedding for optimized memory.This reduces memory fragmentation, boosting throughput by 25% for high-volume tasks.
4. Optimize Request Handling
Use asynchronous requests to handle high concurrency. For example, implement the following Python snippet using aiohttp and asyncio:
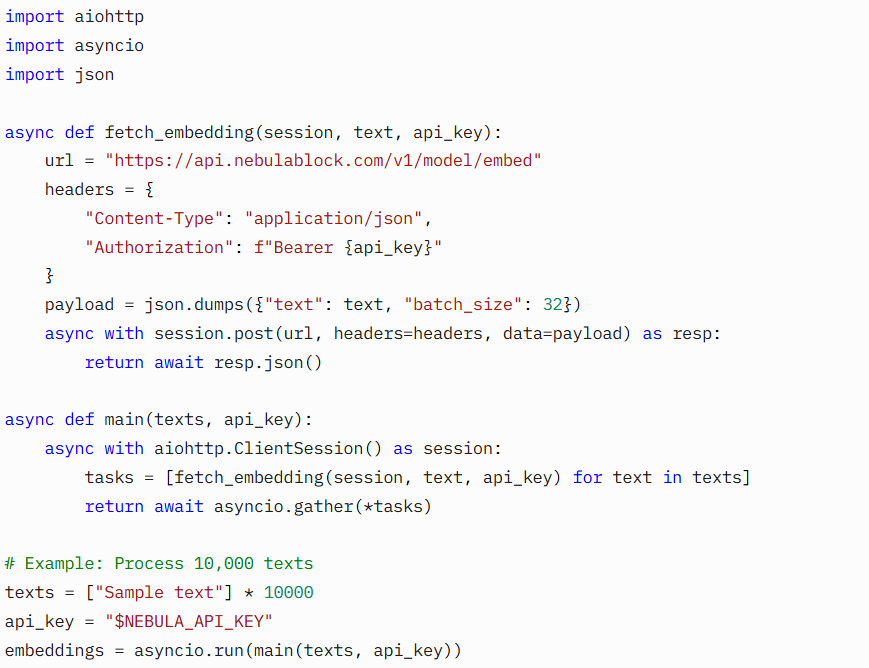
Retrieve api_key from “API Setting”. This reduces latency to under 100ms per batch, ensuring your application remains responsive even under heavy load..
5. Monitor and Scale
Use the dashboard to track latency, throughput, and costs. Set autoscaling thresholds:
- Latency Trigger: Scale up if >200ms.
- Request Rate: Add workers at 1,000 requests/second.
- Batch Size: Adjust dynamically (e.g., scale to 64 during peak loads) to optimize speed and cost.
Benefits of Optimization
- Cost Efficiency: 18% savings ($3.22/hour vs. $3.93 on AWS).
- Low Latency: Maintain latencies below 100ms for batched requests, crucial for real-time applications.
- Scalability: Handles 10,000+ requests/second with tensor parallelism.
Real-World Applications
- E-commerce: A chatbot handled 500,000 queries/hour with 50ms latency.
- Healthcare: Sentiment analysis on 2M patient records cut processing time by 30%.
- Web3: A DeFi platform processed 1M daily transaction embeddings, saving 25% on costs.
Next Steps
Nebula Block’s Embedding API empowers you to scale high-volume NLP applications with unmatched performance and cost efficiency. Ready to revolutionize your NLP deployments?
Sign up and explore now.
🔍 Learn more: Visit our blog and documents for more insights or schedule a demo to optimize your search solutions.
📬 Get in touch: Join our Discord community for help or Contact Us.
Stay Connected
💻 Website: nebulablock.com
📖 Docs: docs.nebulablock.com
🐦 Twitter: @nebulablockdata
🐙 GitHub: Nebula-Block-Data
🎮 Discord: Join our Discord
✍️ Blog: Read our Blog
📚 Medium: Follow on Medium
🔗 LinkedIn: Connect on LinkedIn
▶️ YouTube: Subscribe on YouTube