NVIDIA H200 on Nebula Block: Maximizing AI Throughput for Large Model Training & Inference

The NVIDIA H200 GPU marks a major leap for developers and researchers working with large-scale AI and HPC workloads. As the first GPU equipped with HBM3e memory, the H200 delivers breakthrough performance and memory capacity to accelerate generative AI, large language models (LLMs), and scientific computing. From LLM training to video generation, it's built to handle the most demanding tasks with unmatched efficiency, and is now fully supported on Nebula Block.
Why H200?
The H200 is NVIDIA’s most advanced Hopper-based GPU, featuring:
- 141GB HBM3e memory: double the capacity of previous-gen cards.
- 4.8TB/s memory bandwidth: among the fastest of any widely available data center GPU.
- Up to 1,979 TFLOPS FP16 performance: high throughput for AI and deep learning workloads.
- 900GB/s NVLink interconnect: enables efficient multi-GPU scaling for training and inference.
Perfect for:
- Training large LLMs (e.g. LLaMA-3 70B, Mixtral, DeepSeek).
- High-throughput inference with quantized models (INT4, AWQ).
- Long-context processing (32K+ tokens).
- Diffusion-based video and image generation (ComfyUI, Mochi, Stable Diffusion).
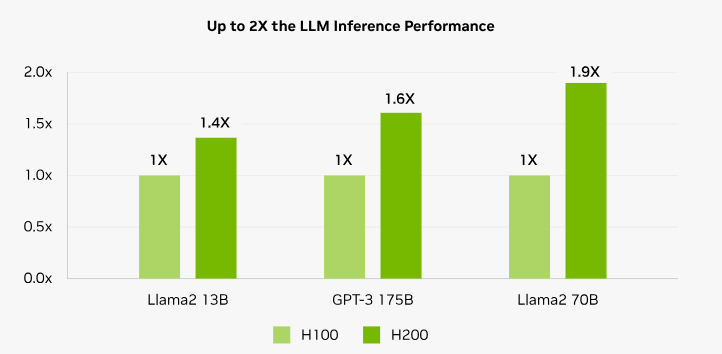
Real-World Performance on Nebula Block
Task | H100 | H200 | Gain |
|---|---|---|---|
Training Throughput | 850 tokens/s | 1,370 tokens/s | +61% |
Inference Latency | 142ms | 89ms | -37% |
Batch Inference | 11 req/s | 18 req/s | +63% |
Benchmarked on 70B+ parameter models. Results may vary slightly by workload.
Optimization Strategy
Nebula Block’s stack is tuned to unlock full H200 potential:
- TensorRT-LLM: Auto-optimized kernels for 70B+ models, boosting token throughput.
- NVLink Topology: Up to 900GB/s interconnect for seamless multi-GPU training.
- Quantization Profiles: Pre-tuned FP8/INT4 modes for faster, memory-efficient inference.
- Flexible access: Use Web UI, CLI, or Jupyter-based notebooks
Scale large model training and inference with streamlined DevOps and high-throughput infrastructure.
Cost-Performance Tradeoffs
Metric | H100 | H200 | Improvement |
|---|---|---|---|
Price per instance | 1.0× | ~1.4× | +40% cost |
Throughput per dollar | 1.0× | ~2.1× | 2.1× value/dollar |
Latency per dollar | 1.0× | ~0.6× | ~40% better efficiency |
Note: Metrics are based on community benchmarks and estimations. Actual performance may vary depending on workload, framework, and quantization.
Deploy H200 on Nebula Block
Maximizing AI throughput for large models requires seamless access to cutting-edge hardware. Here’s how to deploy NVIDIA’s H200 SXM GPUs on Nebula Block in under 3 minutes:
Step 1: Access Your Nebula Block Dashboard
- Sign up Nebula Block account.
- Add payment method in Billing and deposit $10 to start GPU deployment.
Step 2: Deploy H200 Instance
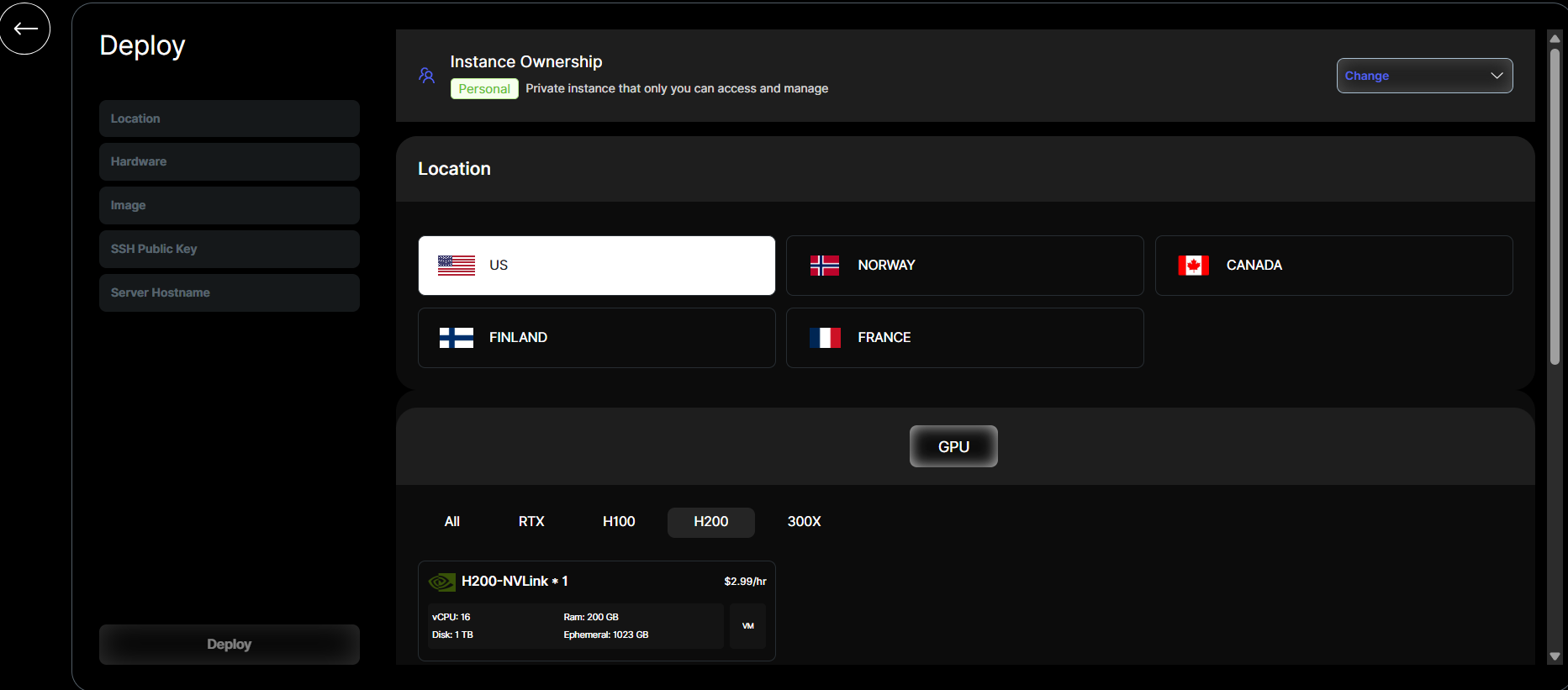
- Navigate to Instances → Continue Deployment.
- Select Country → H200:
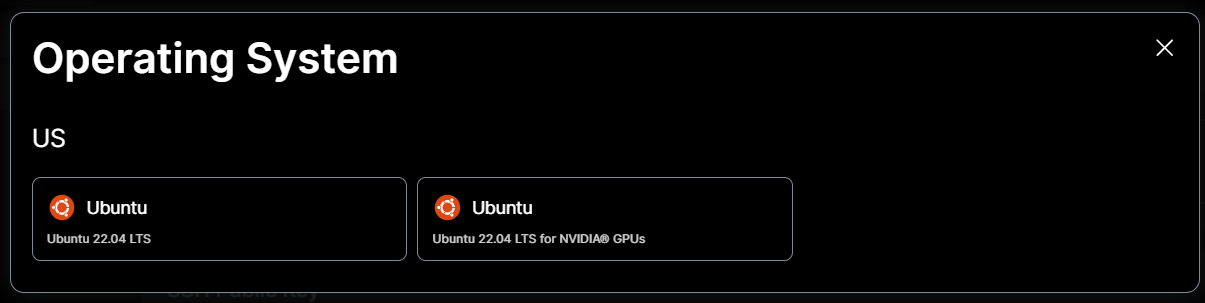
- Choose Operating System:
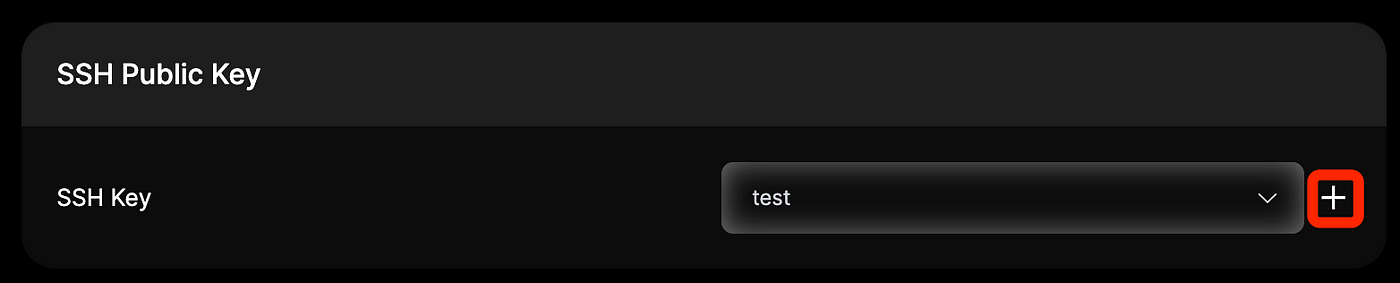
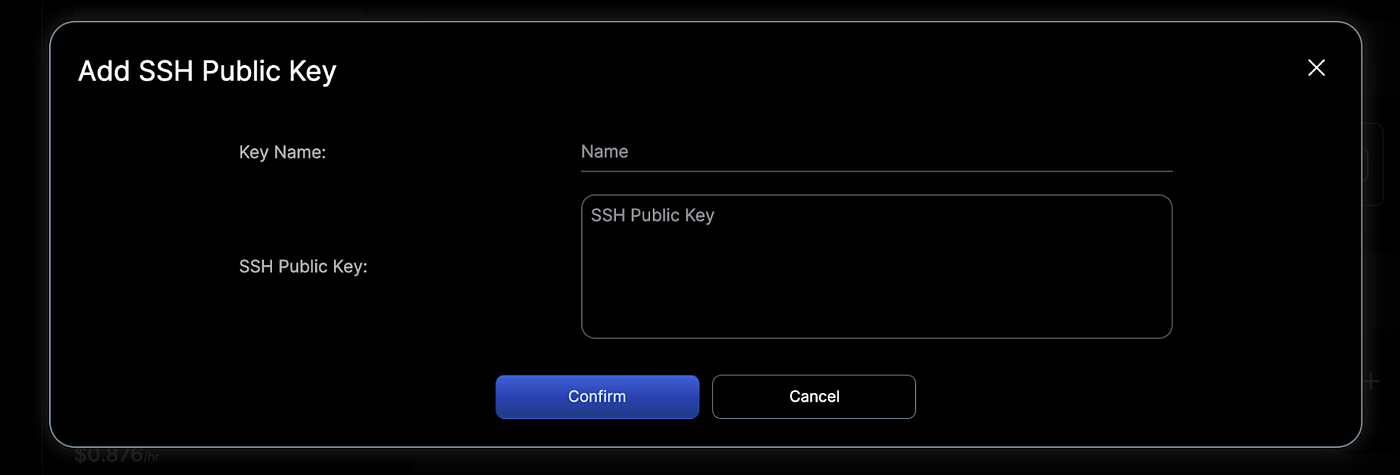
- Add SSH public key for secure access to the instance. If you don’t have one, you can generate it using tools like ssh-keygen and then use the “+” button to save it
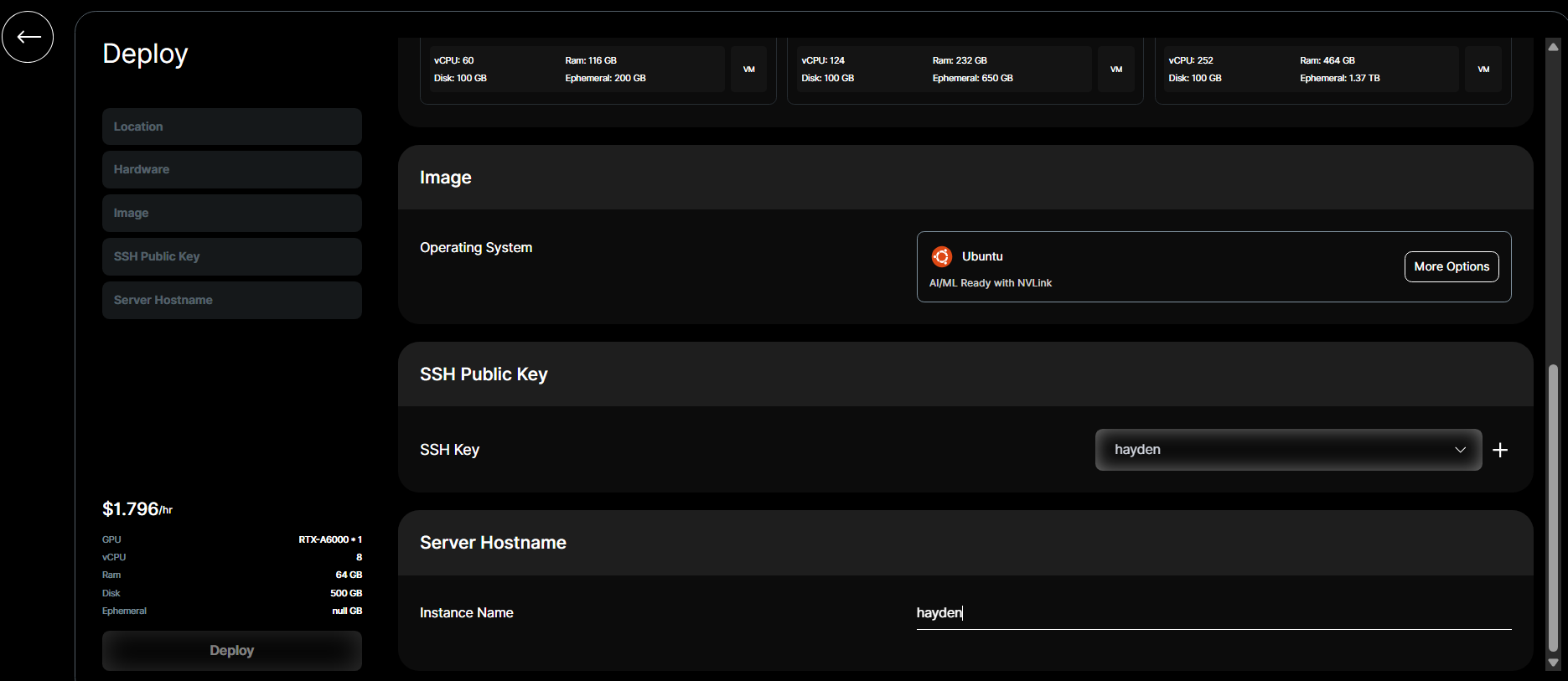
- Set Instance Name and Click "Deploy" - provisioning takes ~1 minute.
Conclusion
For organizations scaling LLMs beyond 70B parameters, H200 on Nebula Block offers a significant performance boost—delivering up to 40–45% higher throughput compared to H100 systems. The NVLink variant is ideal for high-throughput inference and fine-tuning, available immediately in the US, Canada, Finland, and France. For H200 SXM deployments, scheduling a memo through our support team.
Next Steps
Ready to explore? Sign up and explore now.
🔍 Learn more: Visit our blog and documents for more insights or schedule a demo to optimize your search solutions.
📬 Get in touch: Join our Discord community for help or Contact Us.
Stay Connected
💻 Website: nebulablock.com
📖 Docs: docs.nebulablock.com
🐦 Twitter: @nebulablockdata
🐙 GitHub: Nebula-Block-Data
🎮 Discord: Join our Discord
✍️ Blog: Read our Blog
📚 Medium: Follow on Medium
🔗 LinkedIn: Connect on LinkedIn
▶️ YouTube: Subscribe on YouTube