Fine-Tuning vs RAG in LLMs: Choosing the Right AI Strategy for Your Use Case

As organizations increasingly leverage Large Language Models (LLMs) for various enterprise and product applications, understanding how to best integrate knowledge into these models becomes essential. Two prevalent methods for enhancing LLM performance are fine-tuning and retrieval-augmented generation (RAG).
This article explores the pros, cons, and use cases of each approach — helping you choose the best LLM strategy for your business or application.
Understanding Fine-Tuning
Fine-tuning is the process of adapting a pre-trained LLM (such as LLaMA, GPT, or Mistral) by continuing training it on a task-specific dataset. This allows the model to internalize domain-specific language patterns, terminology, and task logic.
Key Characteristics of Fine-Tuning:
- Dataset Dependency: Needs a well-structured dataset aligned with the target task.
- Parameter Adjustment: Tweaks model weights for better performance in a specialized domain.
- Resource Intensive: Demands significant GPU power and time.
- End Result: Tailored to specific tasks but less adaptable to new, untrained queries.
When to Use Fine-Tuning:
- If you have a rich, domain-specific dataset and a clear understanding of the target task.
- You need predictable, highly accurate responses in a narrow domain like legal, finance, or medicine.
- You're deploying a closed-domain assistant where the input patterns are known.
| Pros | Cons |
|---|---|
| ✅ High accuracy on specific, domain-tailored tasks | ❌ Requires large labeled datasets |
| ✅ Model becomes deeply specialized in your use case | ❌ High compute cost (GPU/TPU intensive) |
| ✅ Offline performance (no need for external DB at runtime) | ❌ Less adaptable to unseen or evolving queries |
| ✅ Useful for use cases with strict response formatting | ❌ Longer setup and iteration cycles |
Understanding Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) is a hybrid architecture where the LLM retrieves relevant information from an external knowledge base (like a vector DB) and uses that to generate more accurate, grounded responses. The model itself is not retrained, but instead, it’s guided by dynamic content retrieval.
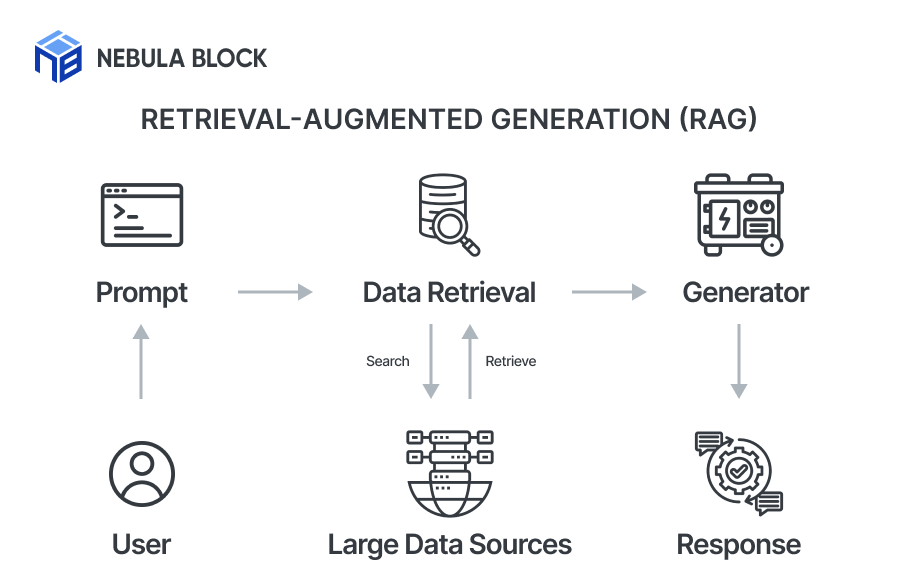
Key Characteristics of RAG:
- Dynamic Knowledge Integration: Pulls contextual data dynamically, adapting to varied queries.
- Reduced Training Requirements: Requires less training and supports frequent updates.
- Flexibility: Accesses external sources for topics beyond original training.
- Lower Compute Demand: Runs efficiently on lightweight GPUs or inference APIs.
- End Result: Combines generative power with context-specific retrieved data.
When to Use RAG:
- The knowledge changes frequently (e.g., product info, user documents).
- The model needs to answer unpredictable or long-tail queries.
- You want real-time adaptation without expensive retraining cycles.
| Pros | Cons |
|---|---|
| ✅ Dynamically integrates external knowledge at runtime | ❌ Depends on the quality and coverage of the knowledge base |
| ✅ Lower resource requirements compared to fine-tuning | ❌ May produce inconsistent or hallucinated outputs if retrieval fails |
| ✅ Quick to set up and maintain | ❌ Slightly higher latency due to document retrieval step |
| ✅ Easily updatable by modifying the knowledge base | ❌ Complex pipeline (retrieval + generation stages) |
Comparing Fine-Tuning and RAG
| Criteria | Retrieval-Augmented Generation (RAG) | Fine-Tuning |
|---|---|---|
| Cost | Low | High |
| Deployment Speed | Fast | Slow |
| Data Update Capability | Easy (just update the knowledge base) | Requires retraining |
| Answer Logic Customization | Limited (depends on retrieved context) | Very high (you control model behavior) |
| Suitability for Private Data | Possible (with private document store) | Excellent (fine-tuned on private dataset) |
| Hardware Requirements | Moderate | High (requires powerful GPUs) |
| Scalability | High | Medium |
| Latency | Higher (retrieval step adds delay) | Lower (direct model response) |
| Accuracy (on known domain) | Depends on retrieval quality | Very high (if trained on relevant data) |
| Maintenance | Simple (update documents only) | Complex (retraining required) |
| Use Case Flexibility | Very flexible | Task-specific |
| Popular Use Cases | Chatbots, search, QA with dynamic info | Specialized assistants (legal, medical, finance) |
Choosing the right strategy is only half the equation — you also need the right infrastructure to support it. That’s where Nebula Block comes in.
Why Nebula Block is Ideal for Fine-tuning and RAG Workloads
Whether you're fine-tuning a foundation model or building a Retrieval-Augmented Generation (RAG) pipeline, Nebula Block gives you the compute flexibility to scale confidently.
Nebula Block is the first Canadian sovereign AI cloud, designed for performance, control, and compliance. It offers both on-demand and reserved GPU instances, spanning enterprise-class accelerators like NVIDIA B200, H200, H100, A100, and L40S, down to RTX 5090, 4090, and Pro 6000 for cost-effective experimentation. Backed by infrastructure across Canada and globally, Nebula Block supports low-latency access for users worldwide. It also provides a wide range of pre-deployed inference endpoints—including DeepSeek V3 and R1 completely free, enabling instant access to state-of-the-art large language models.
Conclusion
In summary, fine-tuning offers precision, while RAG offers flexibility. Choose fine-tuning when accuracy in a defined task is critical and you have curated training data. Choose RAG when agility, scale, and real-time knowledge matter.
Sign up and explore now.
🔍 Learn more: Visit our blog and documents for more insights or schedule a demo to optimize your search solutions.
📬 Get in touch: Join our Discord community for help or Contact Us.
Stay Connected
💻 Website: nebulablock.com
📖 Docs: docs.nebulablock.com
🐦 Twitter: @nebulablockdata
🐙 GitHub: Nebula-Block-Data
🎮 Discord: Join our Discord
✍️ Blog: Read our Blog
📚 Medium: Follow on Medium
🔗 LinkedIn: Connect on LinkedIn
▶️ YouTube: Subscribe on YouTube