Fine-Tuning Large Language Models: Infrastructure Requirements and Best Practices

How Nebula Block Delivers Cost-Effective Infrastructure for LLM Fine-Tuning
Fine-tuning large language models(LLM) has become essential for businesses seeking to customize AI solutions for their specific needs. However, the infrastructure requirements and costs associated with fine-tuning present significant challenges for organizations looking to develop tailored LLM applications.
Today, we explore the critical infrastructure components needed for successful LLM fine-tuning and how Nebula Block’s AI cloud platform addresses these requirements while delivering substantial cost savings.
The Infrastructure Challenge in LLM Fine-Tuning
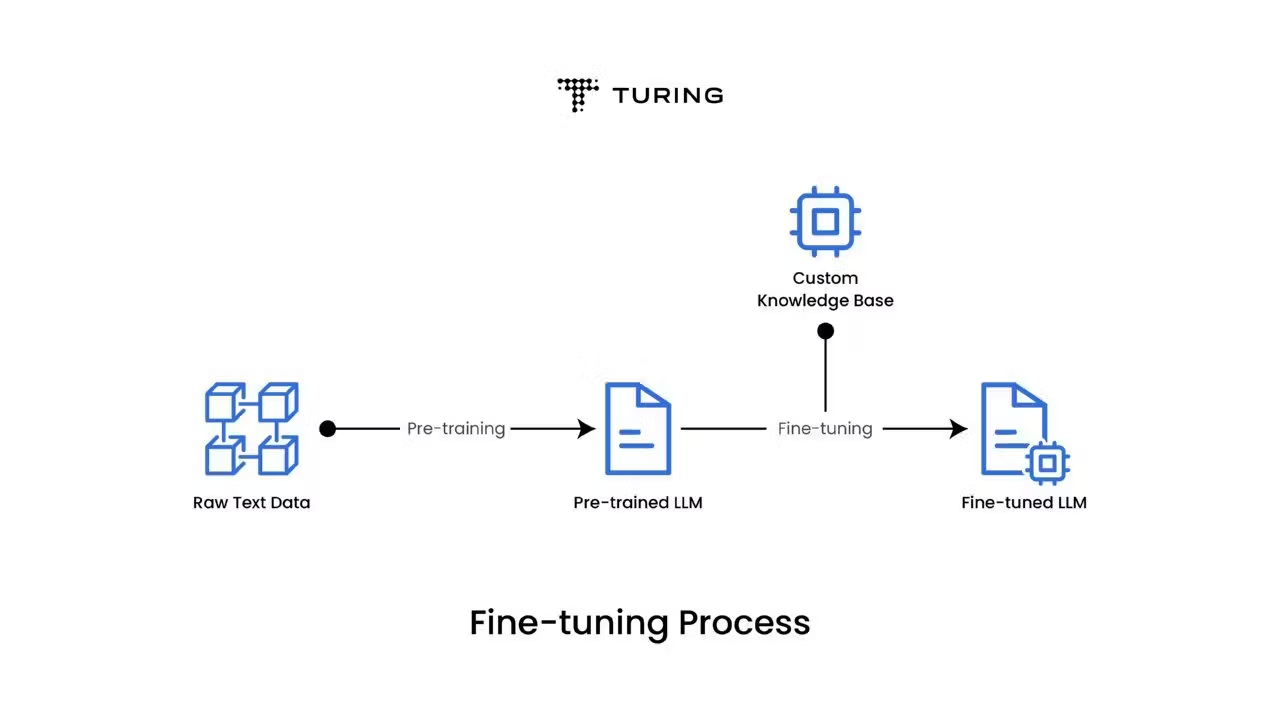
Fine-tuning large language models demands substantial computational resources and sophisticated infrastructure. Organizations must navigate complex trade-offs between performance, cost, and scalability while ensuring their fine-tuning workflows can handle the intensive computational demands of modern LLMs.
The challenge is particularly acute when considering continued fine-tuning (CFT), which involves sequentially fine-tuning models that have already undergone previous training. This approach allows organizations to build upon existing model capabilities while adapting to new tasks, domains, or languages — but requires carefully orchestrated infrastructure to prevent catastrophic forgetting, where models lose previously learned capabilities.
Critical Infrastructure Requirements for Fine-Tuning Success
High-Performance GPU Access
The foundation of effective LLM fine-tuning lies in access to cutting-edge GPU hardware. Modern fine-tuning workflows require GPUs capable of handling large model parameters and extensive datasets efficiently. The latest generation hardware, including NVIDIA H100, RTX 5090, and A100 GPUs, provides the computational power necessary for both training and inference tasks.
Flexible Computing Environments
Successful fine-tuning projects require fully customizable computing environments preloaded with essential AI frameworks. PyTorch, HuggingFace Transformers, FlashAttention, and Fully Sharded Data Parallel (FSDP) have become standard requirements for modern fine-tuning workflows. The ability to configure these environments with full SSH access ensures compatibility with leading open-source models and custom implementations.
Scalable Storage Solutions
Fine-tuning generates substantial amounts of data, from training datasets to model checkpoints and evaluation metrics. S3-compatible object storage that seamlessly integrates with computing services provides the scalability and security necessary for managing these assets throughout the development lifecycle.
Cost-Effective Resource Management
Traditional cloud providers often impose prohibitive costs for the compute-intensive nature of fine-tuning workloads. Organizations need infrastructure solutions that provide enterprise-grade performance at sustainable price points, enabling experimentation and iteration without budget constraints.
Nebula Block: Purpose-Built for AI Workloads
Founded in 2017 with over seven years of expertise in high-performance GPU hosting, Nebula Block operates as an AI cloud platform specifically designed for machine learning and AI development workloads. The platform addresses the critical infrastructure challenges facing LLM fine-tuning through cost-effective, high-performance solutions.
Exceptional Cost Efficiency for Fine-Tuning
Nebula Block’s platform delivers GPU infrastructure at 50% to 80% lower costs than major cloud providers without compromising performance. This cost advantage transforms fine-tuning from an expensive undertaking into an accessible capability for organizations of all sizes, enabling extensive experimentation with different model configurations and datasets.
Cutting-Edge GPU Hardware
The platform provides access to state-of-the-art hardware including RTX 5090, H100, A100, and RTX 4090 GPUs optimized for AI training and inference workloads. This hardware diversity enables organizations to select optimal configurations for their specific fine-tuning requirements, from memory-intensive continued fine-tuning to high-throughput batch processing.
On-Demand GPU Instances for Fine-Tuning
Nebula Block’s on-demand GPU instances offer flexible, rapid deployment of top-tier NVIDIA GPUs with usage-based billing. This model is particularly well-suited for fine-tuning workflows, where computational demands can vary significantly across different training phases. Organizations can scale resources up during intensive training periods and scale down during evaluation or data preparation phases.

Flexible Computing Environments
The platform provides fully customizable computing environments with full SSH access, enabling compatibility with all leading open-source AI models. This flexibility ensures developers can configure their preferred AI frameworks and implement cutting-edge fine-tuning techniques without infrastructure constraints.
Integrated Storage for Model Management
Nebula Block’s S3-compatible object storage seamlessly integrates with computing services, providing efficient dataset and model checkpoint management throughout the fine-tuning lifecycle. This integration is crucial for continued fine-tuning workflows that rely on checkpoint restoration and iterative model development.
Best Practices for LLM Fine-Tuning on Nebula Block
Organizations beginning their fine-tuning journey can start with Nebula Block’s serverless models to experiment with base models like DeepSeek and evaluate potential use cases. The platform’s competitive pricing — including completely FREE access to models like DeepSeek V3 — enables extensive experimentation without financial barriers.

For production fine-tuning workflows, on-demand GPU instances provide the performance and flexibility necessary for sophisticated continued fine-tuning strategies. The platform’s customizable environments and SSH access enable developers to configure their preferred tools and frameworks for seamless transitions from experimentation to production deployment.

The combination of cost-effective pricing, cutting-edge hardware, and optimized environments positions Nebula Block as an ideal platform for organizations looking to implement advanced fine-tuning techniques without the infrastructure complexity and costs associated with traditional cloud providers.
Conclusion
Fine-tuning large language models requires specialized infrastructure that balances performance, flexibility, and cost-effectiveness. Nebula Block’s AI cloud platform addresses these requirements through cutting-edge GPU hardware, optimized computing environments, and pricing that makes sophisticated fine-tuning techniques accessible to organizations of all sizes.
By focusing specifically on AI workloads and delivering substantial cost savings, Nebula Block enables organizations to implement advanced fine-tuning strategies including continued fine-tuning, multilingual adaptation, and iterative model improvement without the budget constraints that traditionally limit AI development.
Ready to Fine-tune smarter? 👉 Start Now
Stay Connected
💻 Website: nebulablock.com
📖 Docs: docs.nebulablock.com
🐦 Twitter: @nebulablockdata
🐙 GitHub: Nebula-Block-Data
🎮 Discord: Join our Discord
✍️ Blog: Read our Blog
📚 Medium: Follow on Medium
🔗 LinkedIn: Connect on LinkedIn
▶️ YouTube: Subscribe on YouTube