Deploying Ollama + WebUI on Nebula Block Instance

This tutorial will guide you through the process of deploying Ollama with a web-based interface (WebUI) on a Nebula Block instance. By following these steps, you will have a fully operational Ollama service running on a GPU-powered instance, accessible via a web browser.
1. Setting Up a Serverless Instance on Nebula Block
Nebula Block provides a serverless environment that allows you to deploy and manage instances without worrying about the underlying infrastructure. Follow these steps to set up your instance:
1.1 Sign Up & Create an Instance
Create an Account:
Visit Nebula Block and sign up for a new account if you don’t already have one. New users receive initial credits to explore the platform.
Deploy an Instance:
- Navigate to the Instances section in the left panel.
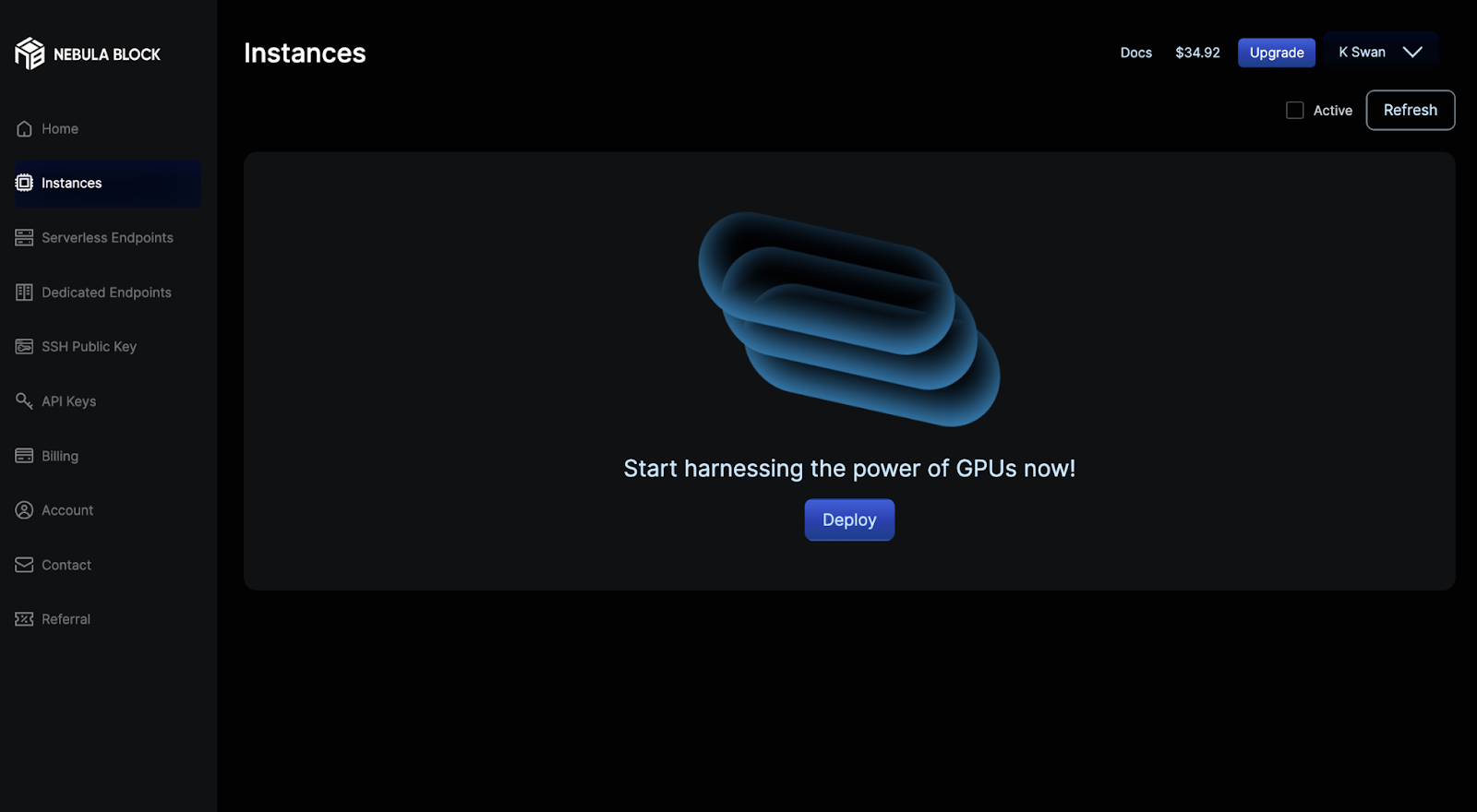
- Click on the Deploy button to create a new instance.
1.2 Configure the Instance
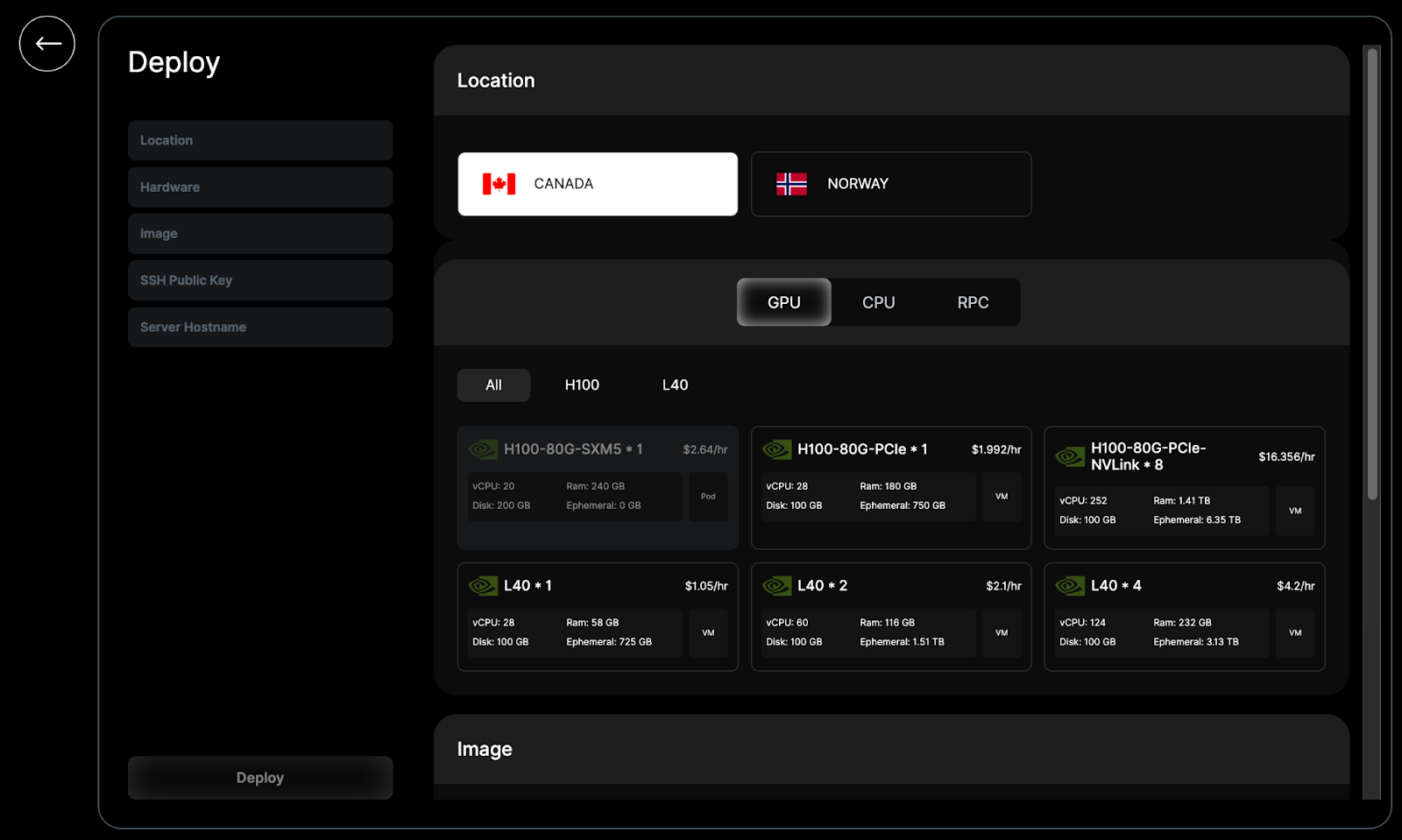
GPU Selection:
Choose a GPU instance type based on your model’s requirements. If you plan to run larger models, select a GPU with sufficient memory.
Operating System:
Select Ubuntu Server 22.04 LTS R550 CUDA 12.4 with Docker as the operating system. This ensures compatibility with GPU-accelerated workloads.
SSH Public Key:
Add your SSH public key for secure access to the instance. If you don’t have one, you can generate it using tools like ssh-keygen and then use the “+” button to save it.
Instance Name:
Assign a name to your instance for easy identification.
Deploy:
Once all fields are filled, click Deploy. Ensure your account has sufficient credits to proceed.
2. Accessing the Instance
After deployment, you can view the instance details in the Instances section.
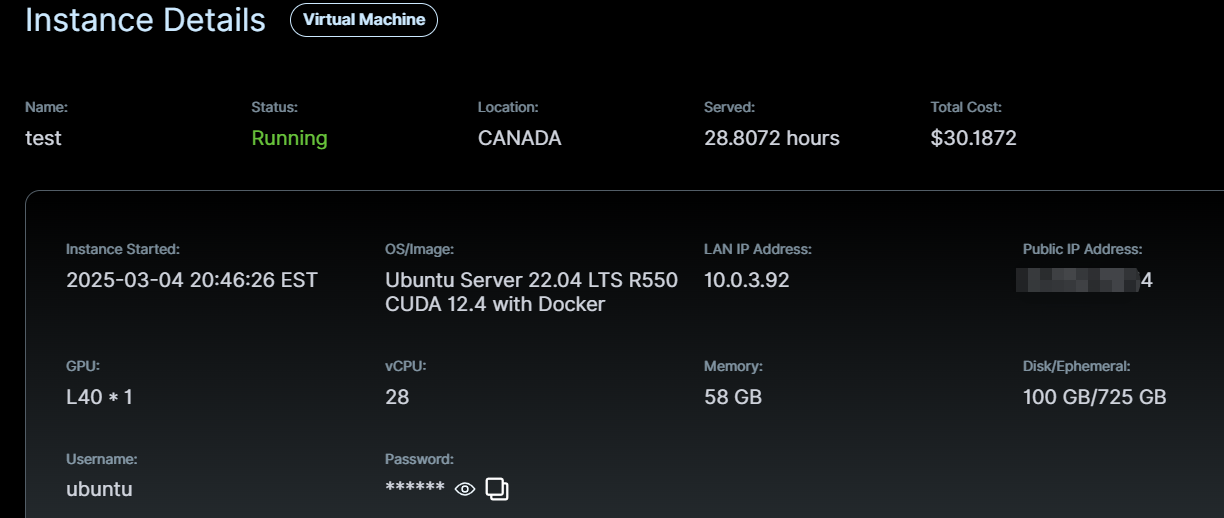
Use the provided Public IP and your SSH key to log into the instance via a terminal:
ssh -i /path/to/your/private_key.pem username@PUBLIC_IPReplace:
/path/to/your/private_key.pemwith the actual path to your SSH private key.usernamewith the appropriate username for your instance (e.g., ubuntu for Ubuntu instances).PUBLIC_IPwith the Public IP address of your instance.
3. Checking GPU Drivers and Docker Service
Once logged in, verify that the GPU drivers and Docker service are running correctly:
Check GPU Status
nvidia-smiIf the output displays GPU details, the drivers are correctly installed.
Check Docker Status
systemctl status dockerEnsure that the Docker service is active and running.
4. Deploying Ollama with WebUI
We’ll use a pre-built Docker image to deploy Ollama along with a web-based interface.
4.1 Run the following Docker command to start the service:
docker run -dit — name ollama — restart=always — gpus all -p 80:8080 swanchain254/ollama-webuiExplanation of the command:
-dit: Runs the container in detached mode with an interactive terminal.— name ollama: Assigns the container the name “ollama”.— restart=always: Ensures the container restarts automatically if it stops.— gpus all: Grants the container access to all available GPUs.-p 80:8080: Maps port 8080 inside the container to port 80 on the server.swanchain254/ollama-webui: Uses the pre-built Docker image.
4.2 Verify the Running Container
To check if the Ollama container is running properly, use:
docker psTo view logs and ensure the service is running:
docker logs -f ollama
5. Accessing the WebUI
Once the container is running, you can access Ollama’s WebUI by opening a browser and navigating to:
http://PUBLIC_IPReplace PUBLIC_IP with your instance’s actual public IP address.
On the WebUI, you can download and run models such as:
- DeepSeek-R1-Distill-Qwen-1.5B
- Llama 2
- Mistral
Conclusion
You have successfully deployed Ollama with a WebUI on a Nebula Block instance. The model is now accessible via a web interface, making it easy to interact with and integrate into your applications. Enjoy your AI-powered experience!
Follow Us for the latest updates via our official channels:
- Website: nebulablock.com
- Twitter: @nebulablockdata
- Discord: Join the Community
- Blog: https://www.nebulablock.com/blog
- Medium: https://nebulablock.medium.com
- LinkedIn: https://www.linkedin.com/company/nebula-block
- YouTube: https://youtube.com/channel/UCkiFox7uP-vKn-ZSpFomz2A