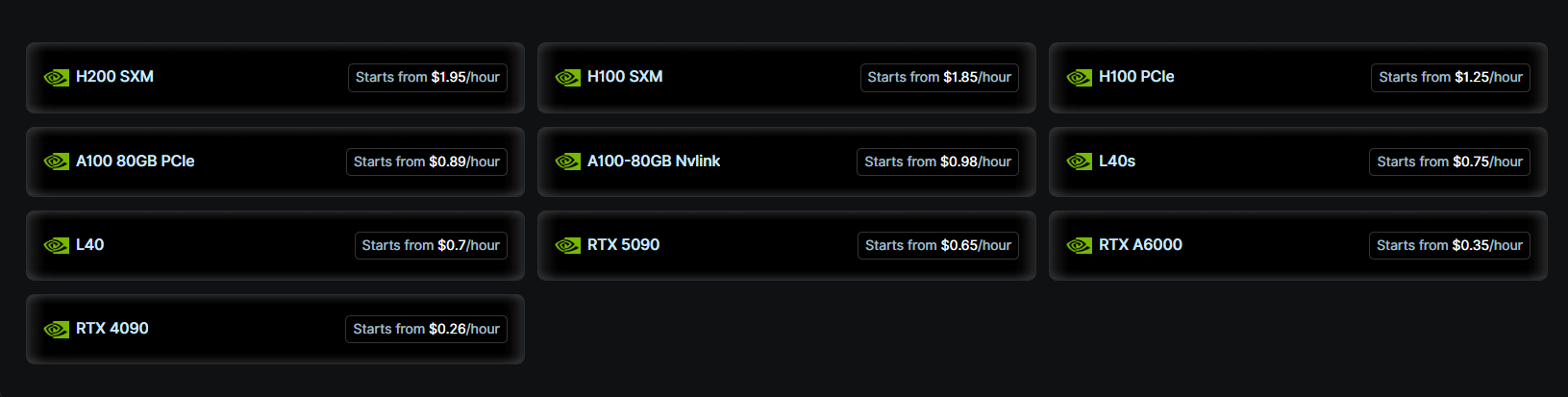
Choosing the Right GPU for Your Workload

As AI and data-intensive applications evolve, selecting the right GPU is no longer just about power — it's about aligning with your specific needs, budget, and deployment strategy. On Nebula Block, you can access a full spectrum of NVIDIA GPUs — from affordable RTX 4090s to enterprise-grade Blackwell B200s — through flexible options like serverless inference, VMs, and bare-metal nodes.
1. Understand Your Workload Type
The first step in choosing a GPU is understanding what kind of tasks you'll be performing. Here's a breakdown:
A. Inference for Lightweight Models (e.g., 7B–13B LLMs)
- Use Case: Chatbots, summarization, embeddings, or other light inference pipelines.
- Recommended GPUs: RTX 4090, RTX 5090, A6000, RTX Pro 6000
- Why: These GPUs offer high compute performance at lower cost. Their 24GB–48GB VRAM can handle most 7B and some 13B models with reasonable batch sizes.
B. Image/Video Generation or Multimodal Inference
- Use Case: Stable Diffusion XL, Pika Labs, Gen-2, etc.
- Recommended GPUs: RTX 4090, A6000, L40S, RTX Pro 6000
- Why: High single-GPU throughput and affordability. Ideal for burst workloads in creative AI.
C. Fine-tuning or Quantization for Mid-size Models (13B–33B)
- Use Case: LoRA/QLoRA training, adapters, reinforcement tuning.
- Recommended GPUs: A100 40GB, A100 80GB
- Why: More VRAM headroom and strong tensor performance, especially for FP16/BF16 formats.
D. Training / Inference for 70B+ Models
- Use Case: LLaMA 2–3, Mixtral, DeepSeek-MoE.
- Recommended GPUs: H100 80GB, B200
- Why: Required for large models due to memory and scaling capabilities. Excellent for multi-GPU setups.
E. Long-context Agents / Advanced Reasoning
- Use Case: Retrieval-augmented generation, agent frameworks like MemAgent or MIRIX.
- Recommended GPUs: H100, H200, B200
- Why: High memory bandwidth, top-tier performance on attention-heavy models.
Specifications Summary Table
This table outlines key specs to further aid your decision-making:
| Specification | NVIDIA H100 | NVIDIA A100 | RTX 4090 | RTX 5090 | B200 |
|---|---|---|---|---|---|
| VRAM | 80 GB HBM3 | 40 or 80 GB HBM2 | 24 GB GDDR6X | 32 GB GDDR7 | 192 GB HBM3e (96 x 2) |
| Memory Bandwidth | 2 TB/s | 1.6 TB/s | 1008 GB/s | 1792 GB/s | 8 TB/s |
| FLOPS (FP32) | 67 TFLOPS | 19.5 TFLOPS | 82.58 TFLOPS | 104.8 TFLOPS | 124.16 TFLOPS (62.08 x 2) |
| CUDA Cores | 14,592 | 6,912 | 16,384 | 21,760 | 33,792 (16,896 × 2) |
| Power Consumption | 350 W | 400 W | 450 W | 575 W | 1000 W |
2. Key Factors to Evaluate
Regardless of use case, consider the following technical aspects:
- VRAM: Determines the model size and batch size you can handle. 24GB is sufficient for 7B; 80GB is better for large-scale jobs.
- Tensor Cores: Accelerate transformer models using mixed precision training.
- CUDA Cores: For general-purpose compute throughput.
- Memory Bandwidth: Impacts training speed and context window size.
- Power Efficiency: Important for long-term workloads (e.g., fine-tuning, inference APIs).
- Interconnect Bandwidth (NVLink / PCIe Gen): Affects multi-GPU communication speed, crucial for distributed training or large batch inference.
- Driver & Framework Compatibility: Ensure support for CUDA versions, PyTorch/TensorFlow builds, and libraries like Triton, TensorRT, or Hugging Face Accelerate.
3. Align with Your Budget
Nebula Block offers flexible pricing models that scale with your workload type and frequency:
- Serverless Inference
Ideal for sporadic use, automation, or production-ready APIs. Pay only for what you use — no setup or idle cost. Best suited for:- Lightweight LLMs or vision inference
- Backend AI for apps and bots
- Developers needing instant GPU without managing infrastructure
- On-Demand VMs
Perfect for experimentation, custom setup, or periodic workloads. You can spin up a VM with pre-installed environments (like Hugging Face, PyTorch, or CUDA) and only pay by the hour. Recommended for:- Model training and evaluation
- Custom pipelines or workflows
- Users needing SSH access or persistent storage
- Reserved Instances
Commit to longer usage (weekly/monthly) and lock in lower rates. Best for:- Ongoing projects with predictable needs
- Teams deploying AI agents in production
- Reducing cloud spending without sacrificing performance
- Bare-Metal Nodes
Best for large-scale training, multi-GPU workflows, or high-performance teams. You get full control of the hardware, dedicated bandwidth, and optimized throughput. Great for:- Distributed training
- Agent frameworks or RAG systems
- Enterprise-grade deployments
💡 Budget Tip:
Start with RTX 4090/5090 for affordable inference or fine-tuning small models. Move up to A100, H100, or B200 for larger models or multi-GPU workloads. If your usage is light and API-based, serverless GPU can be the most cost-efficient option.
4. Final Recommendations
- Use RTX 4090 / 5090 / RTX Pro 6000 for affordable inference and rapid prototyping.
- Use A100 if your model is 13B–33B and you're training or tuning.
- Use H100 / H200 / B200 if you're dealing with 70B+ models, large-scale deployment, or building AI agents.
- Use Nebula’s serverless mode if you need instant, no-maintenance GPU compute.
Choosing the right GPU is a balance between your model's demands and your budget. With Nebula Block's wide GPU range and flexible pricing options, you can find the setup that fits — whether you're running quick inference, tuning mid-size models, or building cutting-edge agents.
Still unsure? Contact our team.
Nebula Block: Canada’s First Sovereign AI Cloud
Nebula Block is the first Canadian sovereign AI cloud, designed for performance, control, and compliance. It offers both on-demand and reserved GPU instances, spanning enterprise-class accelerators like NVIDIA B200, H200, H100, A100, and L40S, down to RTX 5090, 4090, and Pro 6000 for cost-effective experimentation. Backed by infrastructure across Canada and globally, Nebula Block supports low-latency access for users worldwide. It also provides a wide range of pre-deployed inference endpoints—including DeepSeek V3 and R1 completely free, enabling instant access to state-of-the-art large language models.
Next Steps
Sign up and explore now.
🔍 Learn more: Visit our blog and documents for more insights or schedule a demo to optimize your search solutions.
📬 Get in touch: Join our Discord community for help or Contact Us.
Stay Connected
💻 Website: nebulablock.com
📖 Docs: docs.nebulablock.com
🐦 Twitter: @nebulablockdata
🐙 GitHub: Nebula-Block-Data
🎮 Discord: Join our Discord
✍️ Blog: Read our Blog
📚 Medium: Follow on Medium
🔗 LinkedIn: Connect on LinkedIn
▶️ YouTube: Subscribe on YouTube