Virtual Machines vs. Bare Metal: Choosing the Right Infrastructure for AI Training

When building serious AI infrastructure—whether fine-tuning, distributed learning, or production inference—the choice between Virtual Machines (VMs) and Bare Metal can significantly impact performance, cost, and scalability.
With Nebula Block, you can rent GPU-powered virtual machines, containers and bare metal servers tailored to your needs. Let’s break down the trade-offs to help you choose the right setup.
Core Architecture Comparison
| Virtual Machines (VMs) | Bare Metal | |
|---|---|---|
| Architecture | Runs on a hypervisor | Direct access to physical hardware |
| Resource Sharing | Yes – multiple users share hardware | No – fully dedicated hardware |
| Deployment Speed | Fast (seconds to minutes) | Slower (manual or via request) |
| Control & Access | Abstracted via virtualization | Full system-level control |
Performance & Latency
Bare Metal offers the best performance due to zero virtualization overhead. VMs, while efficient, introduce 2–5% latency overhead—though modern GPU virtualization techniques minimize this impact.
Virtual Machines:
- 2–5% latency overhead (due to hypervisor)
- Near-native GPU performance via modern virtualization
- Shared memory and virtual networking
Bare Metal:
- No virtualization overhead
- Full, uncontested GPU memory and compute
- Direct hardware-level networking
✔ Verdict: VMs strike the sweet spot between cost-efficiency and speed, while bare metal unleashes peak performance.
Flexibility & Scalability
| Feature | Virtual Machines | Bare Metal |
|---|---|---|
| Provision Time | Seconds to minutes | Requires coordination |
| Snapshot & Resume | Supported | Not native |
| Scaling | Horizontal scaling on demand | Limited unless pre-reserved |
| Multi-tenancy | Supported | Not applicable |
✔ Verdict: VMs are more flexible and scalable; Bare Metal suits stable, long-running workloads
Security & Isolation
Virtual Machines:
- Software-based isolation between jobs
- Hypervisor adds a secondary security layer
- Ideal for multi-user environments with managed access
Bare Metal:
- Full physical isolation—no shared tenants
- Maximum control over logs, networking, and access
- Ideal for compliance-heavy or enterprise workloads
Cost & Efficiency
| Criteria | Virtual Machines | Bare Metal |
|---|---|---|
| Pricing Model | Pay-per-second (credit-based) | Pay-per-second (credit-based) |
| Entry Cost | Low – great for startups | Higher – suitable for long-term ROI |
| Utilization | Efficient for bursty or short jobs | Efficient for 24/7 inference or training |
| “Virtualization Tax” | Slight loss due to overhead | Full hardware value captured |
Quick Comparison – VM vs. Bare Metal for AI Training on Nebula Block
| Criteria | Virtual Machines (VMs) | Bare Metal Servers |
|---|---|---|
| Performance | Medium (GPU passthrough) | Very High (native hardware access) |
| Provision Speed | Fast | Slower |
| Scalability | Easy to scale | Limited |
| Flexibility | High – supports snapshots, scaling | Lower – best for stable workloads |
| Security | Software-based isolation | Full physical isolation |
| Cost | Lower entry cost, flexible billing | Higher initial cost, better ROI long-term |
| Best for | Iteration, multi-user workloads | LLM training, 24/7 inference, production |
🎯 Decision Framework
| Use Case | Best Option | Why |
|---|---|---|
| Iterating model architectures | Virtual Machines | Fast provisioning, supports snapshots |
| Training multiple small models | Virtual Machines | Easy job parallelism with resource isolation |
| Handling variable or bursty workloads | Virtual Machines | Elastic scaling, cost-efficient |
| Budget-conscious development | Virtual Machines | Pay-as-you-go, lower entry cost |
| LLM training or compute-heavy models | Bare Metal | Dedicated GPU, max throughput |
| Long-running production jobs | Bare Metal | Stable performance without noisy neighbors |
| Custom CUDA or low-level kernel tuning | Bare Metal | Full system access |
| High-availability training or inference pipelines | Bare Metal | Predictable capacity, physical isolation |
| Needing maximum memory/GPU compute | Bare Metal | Full access with no virtualization loss |
Deploy on Nebula Block in minutes:
While Nebula Block also supports bare metal, our current infrastructure roadmap prioritizes VM-based deployment for faster provisioning, greater flexibility, and seamless developer experience. Here's how:
- Navigate to Instances -> "Continue Deployment"
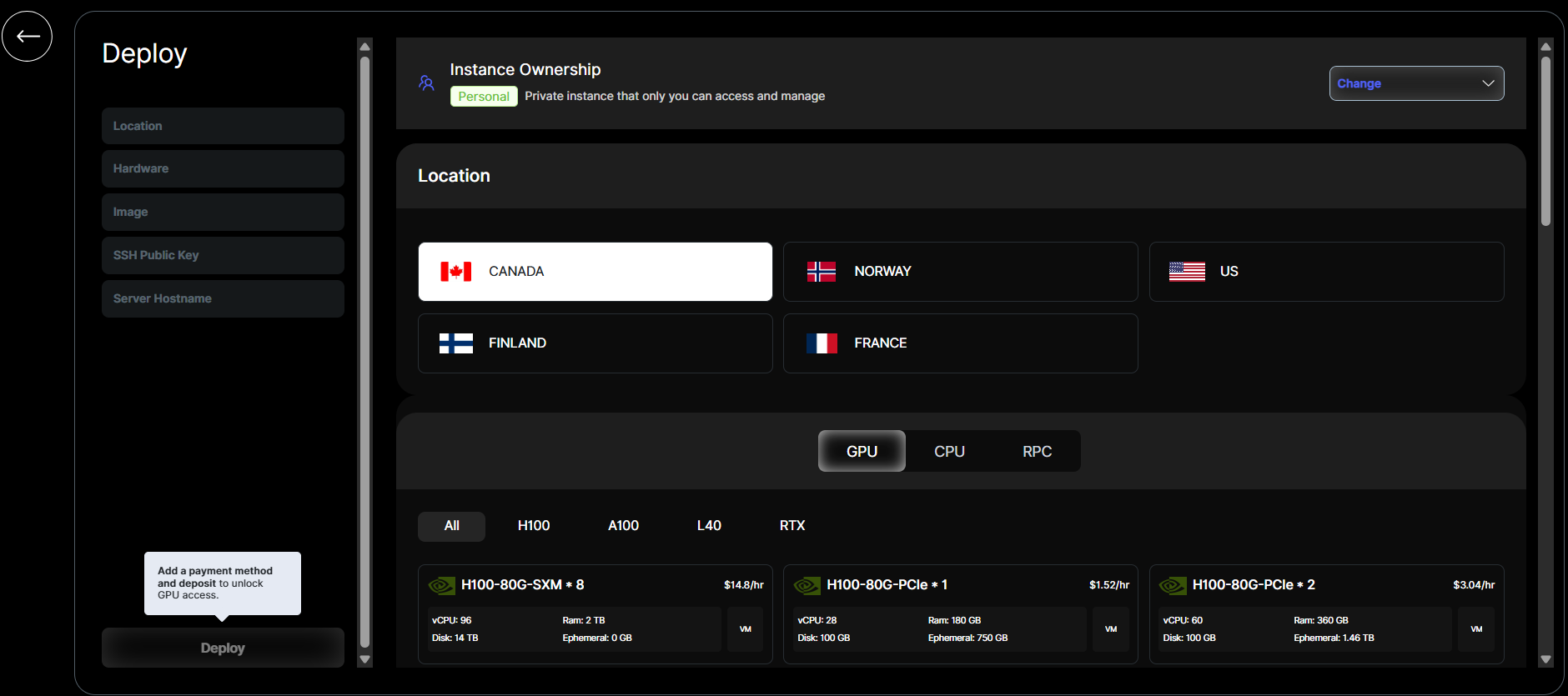
- Choose your preferred location and CPU/GPU configuration
- Choose the Operating system:

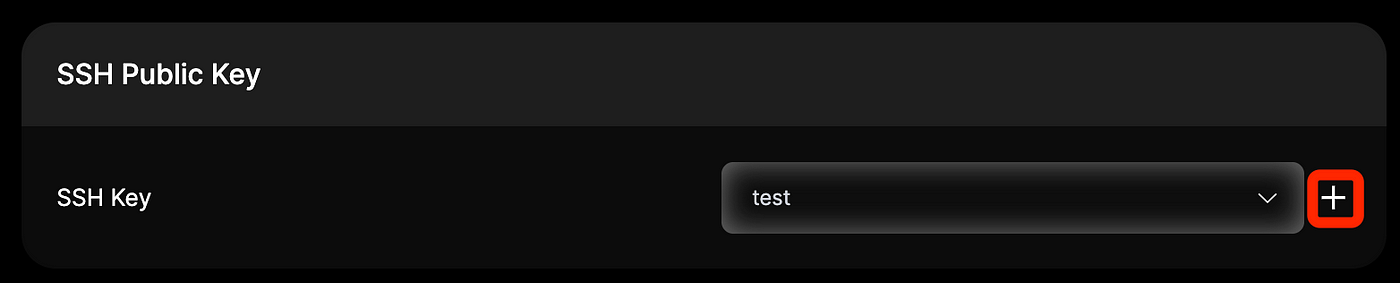
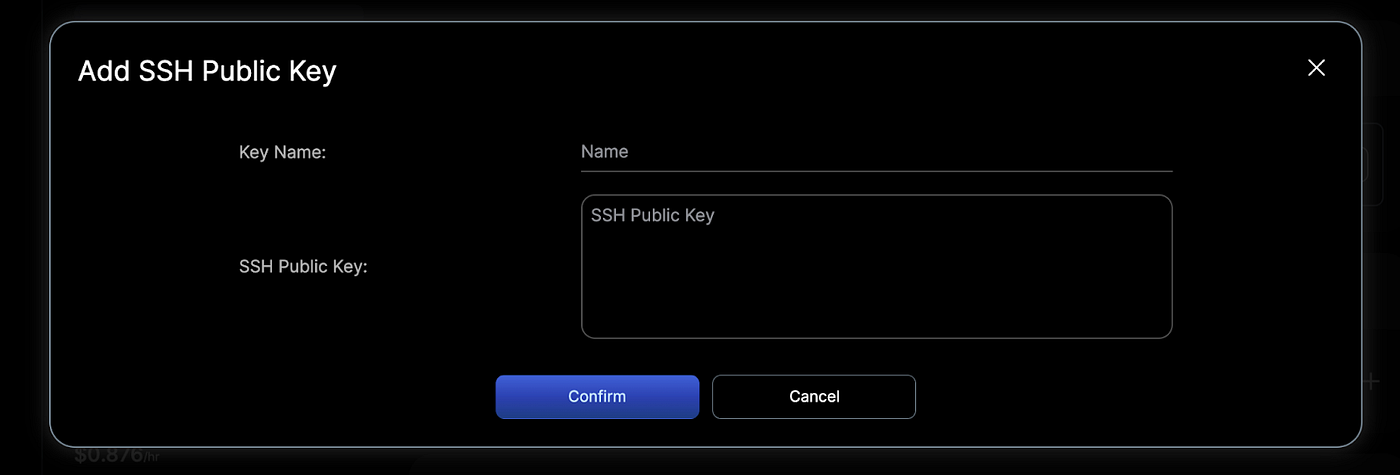
- Add your SSH public key for secure access to the instance. If you don’t have one, you can generate it using tools like ssh-keygen and then use the “+” button to save it
- Set Instance name and click "Deploy"
After running, you can follow the steps in Nebula Block's dashboard to access the instance, it will look like:
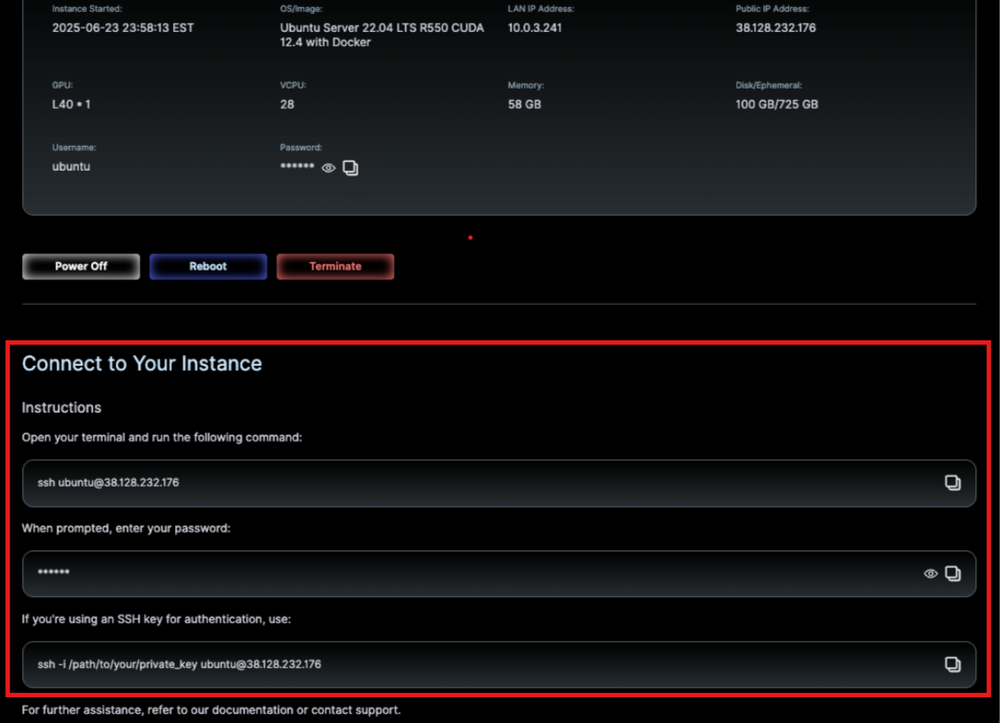
Reminder: Deposit $10 or more to upgrade to Engineer Tier 3 and unlock GPU deployment permissions.
Want More Control? Use Reserved GPU Instances
For teams running longer AI jobs or fine-tuning large models, Nebula Block offers Reserved Instances — dedicated GPUs at up to 40% lower effective cost.
- Lock in high-performance GPUs like A100, H100, B200 and more
- Guaranteed availability, no queueing
- Ideal for production or scheduled training runs
Pay less, worry less — with the same speed and support.
Final Thoughts
For most AI builders, it's always a balance between speed, cost, and flexibility. Whether you're training large models or running dynamic experiments, having access to scalable and reliable infrastructure matters. With Nebula Block, teams get the resources they need to move fast and build confidently.
Next Steps
Sign up and explore now.
🔍 Learn more: Visit our blog and documents for more insights or schedule a demo to optimize your search solutions.
📬 Get in touch: Join our Discord community for help or Contact Us.
Stay Connected
💻 Website: nebulablock.com
📖 Docs: docs.nebulablock.com
🐦 Twitter: @nebulablockdata
🐙 GitHub: Nebula-Block-Data
🎮 Discord: Join our Discord
✍️ Blog: Read our Blog
📚 Medium: Follow on Medium
🔗 LinkedIn: Connect on LinkedIn
▶️ YouTube: Subscribe on YouTube