Unlocking Advanced NLP with Nebula Block Embeddings: A Technical Deep Dive

Introduction
Nebula Block’s Embeddings Endpoint empowers developers to harness state-of-the-art text representation models for tasks like semantic search, RAG (Retrieval Augmented Generation), and content classification. This article explores its architecture, integration workflows, and practical applications, with a focus on bridging the gap between research and production.
What Are Embeddings?
Embeddings are dense vector representations of text that capture semantic meaning. Unlike sparse one-hot encoding, embeddings map words, sentences, or documents into a continuous vector space where similar items cluster closer together. Key applications include:
- Semantic Search: Identify contextually relevant content.
- Clustering: Group similar documents or user profiles.
- RAG Systems: Augment LLMs with external knowledge.
- Classification: Tag content by topic or sentiment.
How Embeddings Work
- Representation: Words are represented as fixed-size vectors in a continuous space, with dimensions like 100, 300, or 512, regardless of the vocabulary size.
- Contextual Meaning: Unlike one-hot encoding, which just gives an index, embeddings capture word meanings. Similar words (e.g., “king” and “queen”) are represented by vectors that are close in the space.
- Training: Embeddings are trained on large text corpora using methods like Word2Vec, GloVe, or BERT, which place similar words near each other in high-dimensional space.
- Dimensionality Reduction: Instead of handling millions of unique words, embeddings reduce them to vectors in a smaller space, making processing more efficient.
- Usage in Models: These vectors are used in machine learning models for tasks like sentiment analysis or translation.
- Beyond Words: Embeddings can also represent sentences, paragraphs, or even items like products, where similar entities are close together in the space.
In Large Language Models (LLMs)
- Memory Layer: In LLMs, embeddings act as the “memory” of the model. They store the semantic meaning of words or phrases as vectors in a high-dimensional space.
- Pre-training: During pre-training, LLMs like BERT learn embeddings by predicting missing words (masked tokens) in large text datasets. This helps the model understand relationships between words based on context.
- Fine-tuning: After pre-training, the model can be fine-tuned on specific data (e.g., legal or medical texts). This helps adjust the embeddings to capture domain-specific meanings and terminology.
Downstream Tasks: Once trained, embeddings are used in various NLP tasks, such as text classification, question answering, or translation. The embeddings feed into the model’s layers, helping it understand the context and make predictions. - Contextuality: Unlike traditional embeddings, LLMs like BERT generate contextual embeddings. This means the representation of a word can change depending on its context. For example, the word “bank” might have different embeddings in “river bank” vs. “bank account.”
Nebula Block Embeddings: A Cutting-Edge Solution
Nebula Block introduces a state-of-the-art embeddings endpoint that stands out with several key features:
Supported Models

WhereIsAI/UAE-Large-V1
- Architecture: Transformer-based, optimized for long-context tasks.
- Use Case: Ideal for enterprise-scale RAG, legal document analysis, and cross-lingual similarity tasks.
BGE-large-en-v1.5
- Architecture: Enhanced version of Beijing Academy of AI’s (BAAI) Bidirectional Encoder, fine-tuned with contrastive learning.
- Use Case: Perfect for real-time applications like chatbots, e-commerce product matching, and low-latency semantic search.
Model Expansion Roadmap:We will continue to add top open-source embeddings models to our platform. Developers can request new models by filling out form here: https://www.nebulablock.com/contact
Stay tuned for updates!
Integration and Usage
Multiple Call Methods

Nebula Block Embeddings can be accessed through various methods:
- Python
- cURL
- JavaScript
- OpenAI-compatible API
Example: OpenAI API Compatibility
The Nebula Block Embeddings endpoint has full OpenAI compatibility so if you have already built your applications following the OpenAI API, you can easily switch it out:
from openai import OpenAI
client = OpenAI(api_key=TOGETHER_API_KEY, base_url="https://inference.nebulablock.com/v1/embeddings")
def get_embedding(text, model="WhereIsAI/UAE-Large-V1"):
text = text.replace("\n", " ")
return client.embeddings.create(input = [text], model=model).data[0].embedding
Building a RAG Application with Nebula Block
One of the most popular use cases of embedding models is building a Retrieval Augmented Generation (RAG) system. You can now create your RAG application using Nebula Block inference API, Embedding API and popular frameworks such as GraphRAG and LangChain.
Telegram Bot Example with GraphRAG
To demonstrate the power of Nebula Block embeddings, we’ll walk through a practical example of creating a sophisticated Telegram bot that can understand and respond to context with remarkable accuracy. The implementation leverages several key libraries and code structures, which allow the bot to process complex queries and provide detailed answers.
Here’s an overview of the code involved in building this RAG-powered bot:

End Result:
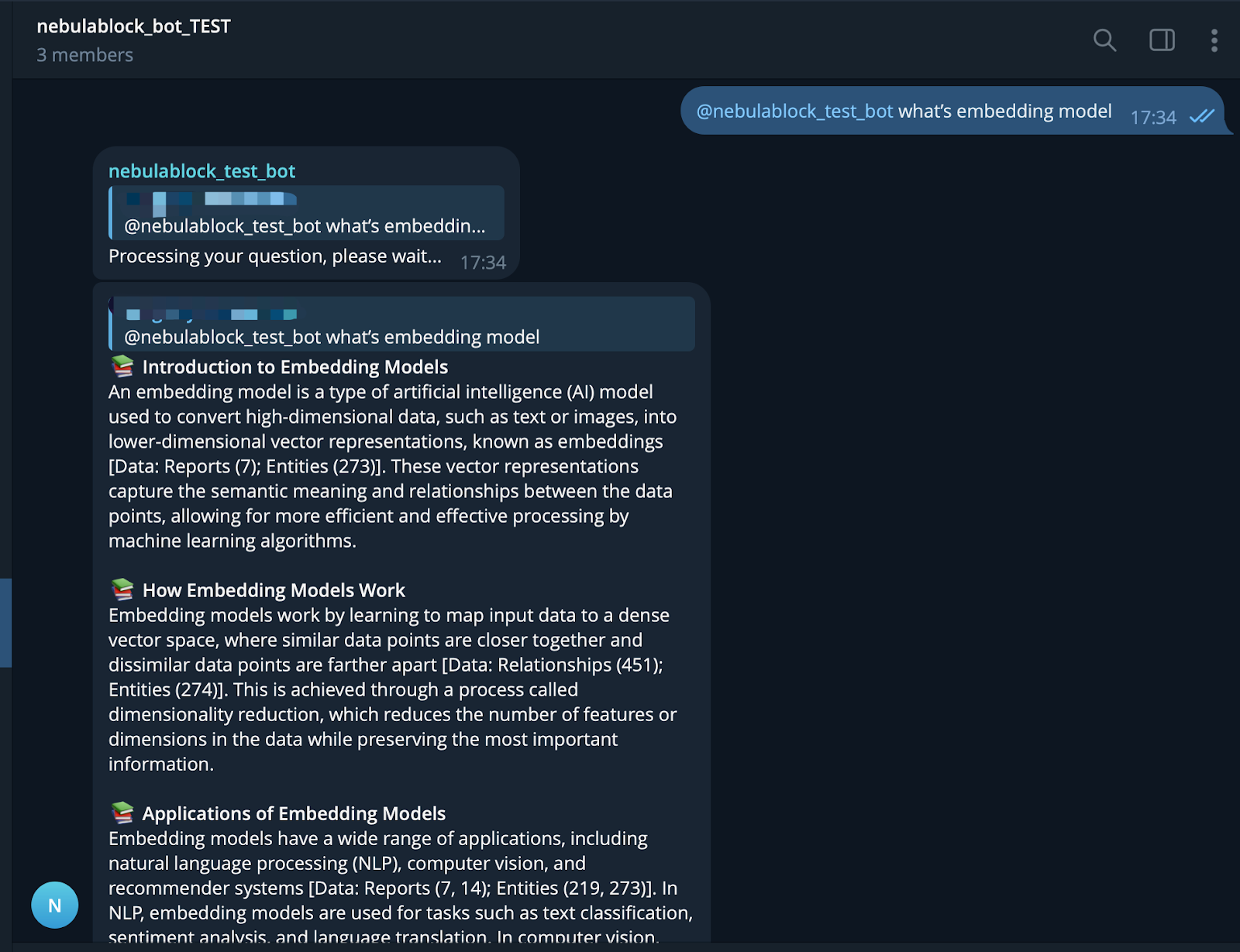
Once the bot is set up with the integration code, it can respond to interactive queries within seconds. The bot pulls contextually relevant information from the indexed documentation, powered by Nebula Block embeddings and GraphRAG technology.
The bot excels at answering complex, contextual questions with accurate responses, ranging from technical specifications to conceptual explanations.
Here’s a glimpse of the final result — the Telegram bot interaction, showcasing the seamless performance:
Conclusion
Nebula Block’s Embeddings Endpoint redefines NLP pipelines by combining OpenAI compatibility, cutting-edge models, and scalable infrastructure. Whether you’re building a semantic search engine or refining a RAG system, it offers the precision and flexibility needed for modern AI applications.
Get Started Today:
Click here to sign up!
References:
- Breaking New Ground in Semantic Textual Similarity with UAE Large-V1
- Together AI Embeddings Benchmark
Follow Us for the latest updates via our official channels:
- Website: nebulablock.com
- Twitter: @nebulablockdata
- Discord: Join the Community
- Blog: https://www.nebulablock.com/blog
- Doc: https://docs.nebulablock.com
- LinkedIn: https://www.linkedin.com/company/nebula-block/
- YouTube: https://youtube.com/channel/UCkiFox7uP-vKn-ZSpFomz2A