Store, Serve, Scale: Unlock AI Pipelines with Nebula Block Object Storage

Whether you're fine-tuning a language model or powering real-time inference, the backbone of any scalable AI pipeline is efficient, accessible storage. With Nebula Block’s S3-compatible Object Storage, you get the flexibility and control to move faster—from experimentation to production—without touching heavy infrastructure.
🔹 Store: Foundation for Your ML Workflows
Nebula Block lets you host everything from model checkpoints to training datasets and pipeline assets in a secure, encrypted storage layer:
- Fully compatible with S3 tools like
boto3, AWS CLI, and Cyberduck - Supports public and private buckets
- Works seamlessly with fine-tuned models, RAG pipelines, and multimodal stacks
🔹 Serve: Turn Stored Models into APIs
Once stored, your models can be deployed to GPU-backed runtimes or serverless endpoints in minutes. Nebula Block supports:
- Instant mounting from Object Storage to inference containers
- OpenAI-compatible APIs for serving LLMs
- Support for vLLM, DeepSeek, Claude, Llama.cpp, and more
🔹 Scale: Build Beyond Single Use Cases
With Nebula Block’s modular design, you can go from single deployment to full-stack AI systems:
- Train and fine-tune on A100/H100/H200 GPUs
- Feed documents into RAG frameworks like LangChain or LlamaIndex
- Serve thousands of requests with automatic scaling and per-second billing
It’s not just object storage—it’s the connective tissue of your AI infrastructure.
How to store with Nebula Block?
- Navigate to Object Storage
- Select "Continue Creating Object Storage"
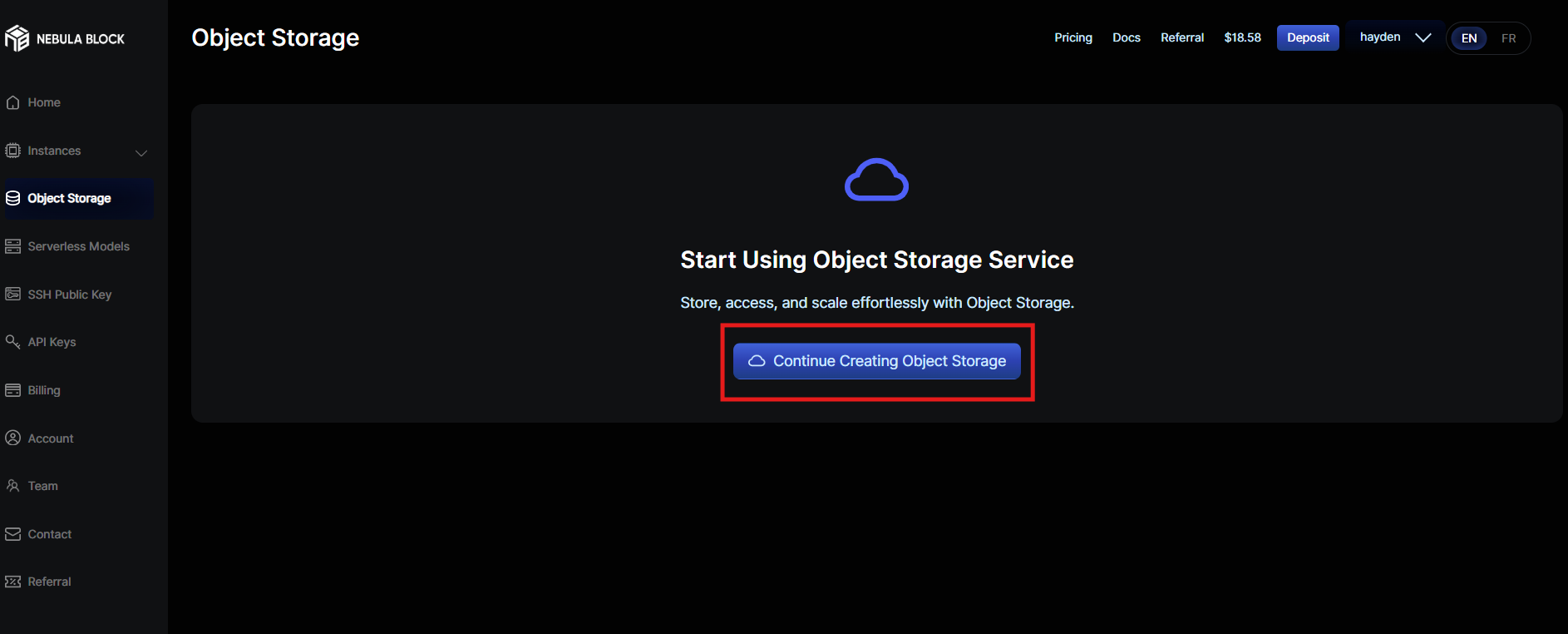
- Select "Ownership", set the "Label", "Storage Type" and "Location"
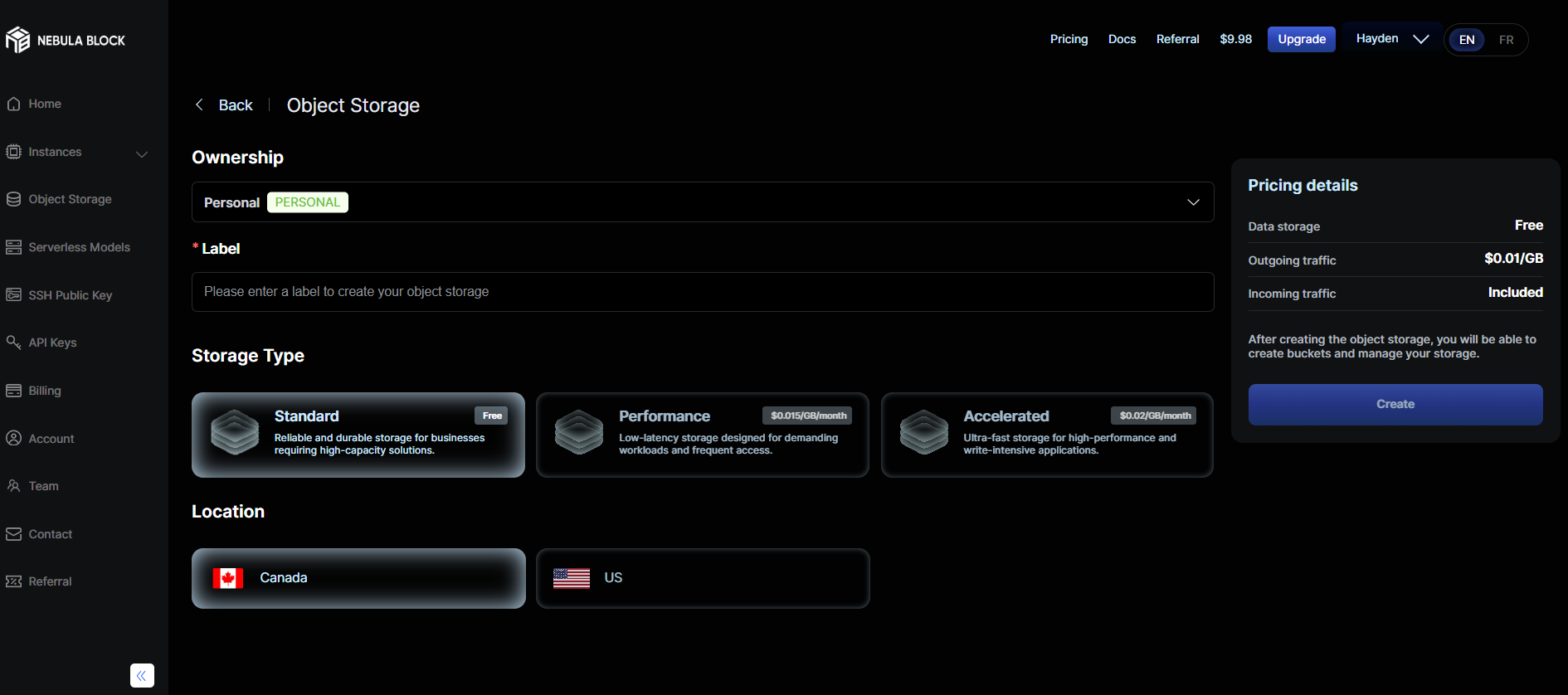
- "Create" and the Dashboard will show information like this:
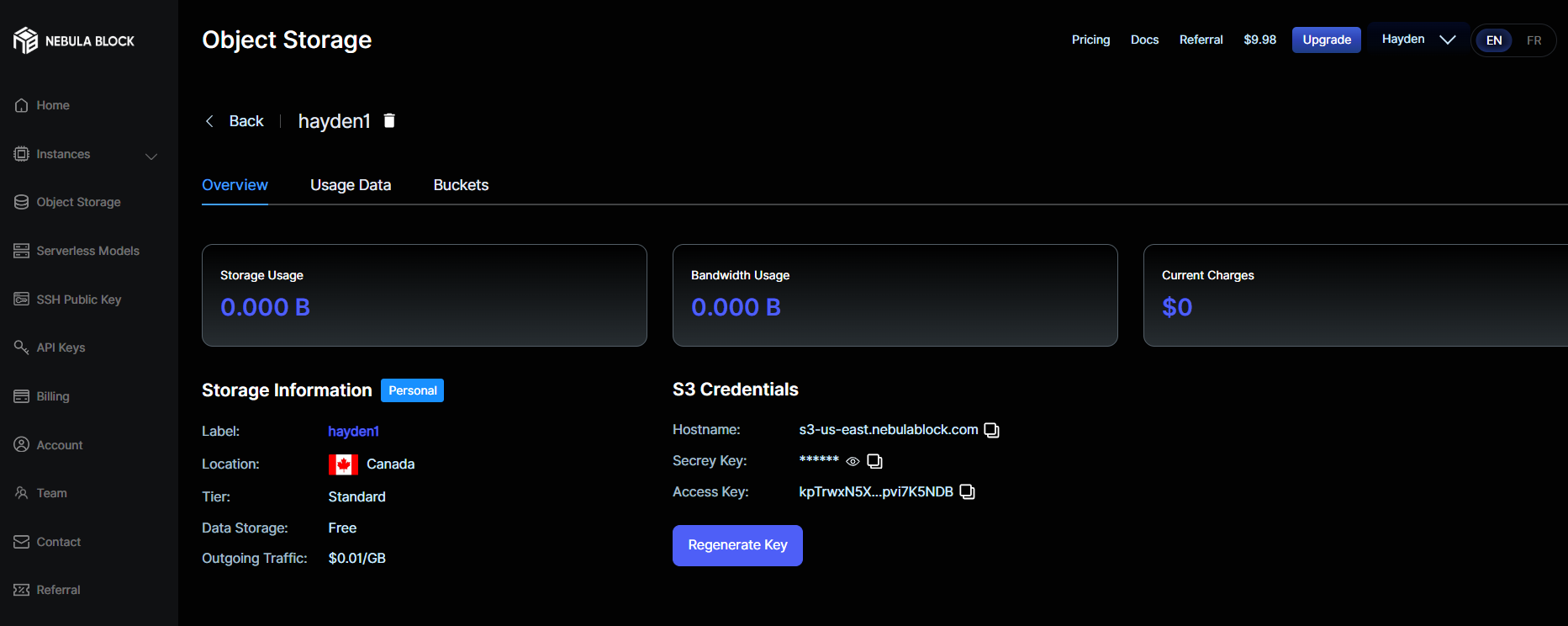
- Select "Buckets", set the Name and "Create"
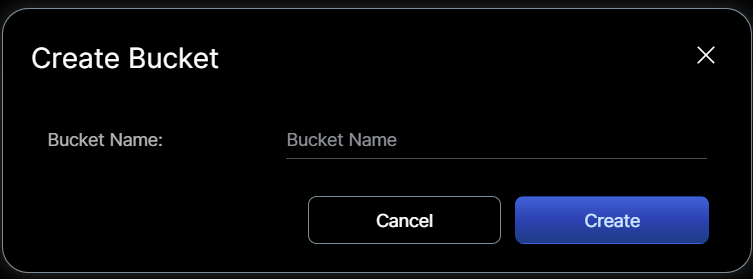
Note: You can set the privacy status of the Buckets. When public, objects can be accessed directly via permanent URL. When private, you must generate a time-limited download link.
Step-by-Step: Use Nebula Block Object Storage (S3-compatible)
Nebula Block’s Object Storage is fully S3-compatible, meaning you can easily upload, store, and manage files — just like using AWS S3, but with simpler pricing and faster setup. To interact with Object Storage using Python, follow these steps:
1. Locate Your Access Information
From the dashboard:
- Endpoint (Hostname): e.g.,
s3-us-east.nebulablock.com - Access Key / Secret Key: Copy from your “S3 Credentials” section
- Bucket Name (automatically created when you set up storage)
2. Connect Using Python (boto3)
- Install dependencies
pip install boto3 python-dotenv- Create a
.envfile in your working directory:
NEBULA_ACCESS_KEY=YOUR_ACCESS_KEY #Use the Access Key from the Details page.
NEBULA_SECRET_KEY=YOUR_SECRET_KEY #Use the Secret Key from the Details page.
NEBULA_ENDPOINT=YOUR_ENDPOINT_URL #Use the Hostname from the Details page.
NEBULA_REGION=YOUR_REGION #Optional, default None.
NEBULA_BUCKET=YOUR_BUCKET_NAME- For a full working script, check out our Upload/Download File Demo.
- Run the Code
python your_script_name.pyMake sure to have theboto3andpython-dotenvlibraries installed and your.envfile properly configured with your Nebula Block credentials.
3. Tips for Usage
- Public access: If the object is public, it can be accessed via a permanent URL.
- Private access: You’ll need to generate a signed (temporary) download link using the Nebula API (coming soon).
- Use Cases:
- Host fine-tuned LLMs or checkpoints
- Store datasets for inference pipelines
- Feed documents into a RAG system (like LangChain, LlamaIndex)
- Pricing:
- Storage: Free
- Outgoing Traffic: $0.01 per GB
Use Cases
- Host your fine-tuned LLMs and load them into Nebula GPU endpoints
- Serve assets for AI inference, apps, or data pipelines
- Store training datasets, logs, or large files securely
- Integrate directly into tools like LangChain, LlamaIndex, etc.
Why This Is Game-Changing
Nebula Block's architecture is optimized for speed, flexibility, and cost-efficiency:
| Feature | Benefit |
|---|---|
| Zero Setup | No containers, no hosting, no infra |
| Per-Second GPU Billing | Only pay for what you use |
| Cold Storage Support | Serve large models without local copying |
| OpenAI-Compatible API | Plug into existing tools and libraries |
| Serverless Deployment | Scale instantly, no warmup needed |
Final Thoughts
You’ve fine-tuned the model — now serve it like a pro. With Nebula Block, your weights in object storage are just one API call away from real-time inference. Host models like code, mount like data, and serve at GPU speed — without touching infra today.
Next Steps
Sign up and explore now.
🔍 Learn more: Visit our blog and documents for more insights or schedule a demo to optimize your search solutions.
📬 Get in touch: Join our Discord community for help or Contact Us.
Stay Connected
💻 Website: nebulablock.com
📖 Docs: docs.nebulablock.com
🐦 Twitter: @nebulablockdata
🐙 GitHub: Nebula-Block-Data
🎮 Discord: Join our Discord
✍️ Blog: Read our Blog
📚 Medium: Follow on Medium
🔗 LinkedIn: Connect on LinkedIn
▶️ YouTube: Subscribe on YouTube