Llama Prompt Ops Released: What It Means for AI Prompt Engineering

The Evolution of AI Prompting
Prompt engineering has become a critical factor in optimizing large language models (LLMs). As AI adoption grows, developers face challenges in structuring prompts effectively to ensure consistent, high-quality responses. Meta’s latest release, Llama Prompt Ops, addresses this issue by automating prompt optimization for Llama models, reducing manual trial and error.
What is Llama Prompt Ops?
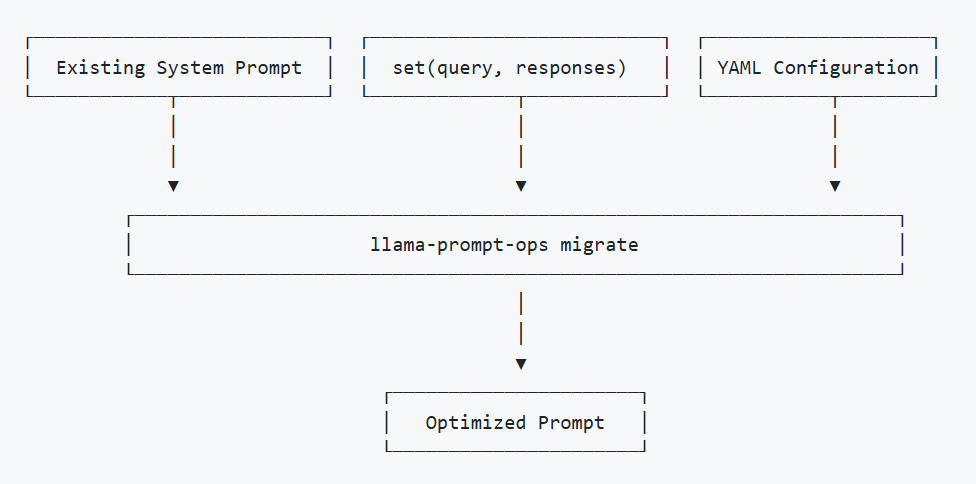
Llama Prompt Ops is an open-source Python library that automates prompt optimization for LLaMA models. Built on DSPy’s MIPROv2 optimizer, it:
- Reduces compatibility gaps when migrating from proprietary LLMs (e.g., GPT-4, Claude).
- Accepts YAML/JSON inputs to simplify prompt structuring.
- Optimizes prompts for tasks like sentiment analysis, RAG-based search, and logical reasoning, minimizing manual trial-and-error.
What’s New in Llama Prompt Ops?
Llama Prompt Ops introduces several key features that enhance prompt structuring and inference efficiency:
- Automated Prompt Optimization → Reduces token waste and improves response accuracy.
- Context-Aware Formatting → Ensures prompts align with model-specific behaviors.
- Seamless Integration → Works with Llama models across various AI applications.
This release is These improvements make Llama Prompt Ops a valuable tool for developers looking to streamline AI interactions without excessive manual adjustments.valuable for developers transitioning from proprietary models like GPT or Claude, as it ensures seamless adaptation without requiring extensive retraining.
How It Compares to Existing Prompting Methods
Traditional prompt engineering relies on manual adjustments and iterative testing. Llama Prompt Ops automates this process, making it easier to achieve consistent, high-quality responses. Compared to existing methods:
- Less manual tuning → Reduces time spent refining prompts.
- Improved token efficiency → Optimizes memory usage for inference.
- Better response consistency → Ensures structured outputs across different tasks.
Scaling AI Inference with Nebula Block
While Llama Prompt Ops focuses on prompt optimization, deploying AI models efficiently requires scalable infrastructure. This is where Nebula Block excels—offering serverless AI compute powered by NVIDIA H100/H200 GPUs. Developers leveraging Llama models can benefit from:
✅ Cost-efficient AI inference: 30-70% cheaper GPU inference vs. competitors.
✅ Kubernetes Autoscaling: Handles traffic spikes seamlessly.
✅ Unified API Endpoints: Simplifies integration into applications.
By combining Llama Prompt Ops for structured prompting with Nebula Block’s scalable AI infrastructure, developers can optimize both prompt efficiency and inference performance.
Final Thoughts: The Future of AI Prompt Engineering
Llama Prompt Ops represents a major leap forward in AI prompting, making structured interactions more accessible to developers. As AI models continue to evolve, tools like this will play a crucial role in enhancing inference efficiency and reducing deployment complexity.
Next Steps for Developers
- Optimize: Experiment with Llama Prompt Ops (GitHub).
- Deploy: Use Nebula Block for scalable, cost-efficient inference.
- Integrate: Merge optimized prompts with dynamic infrastructure for end-to-end AI solutions.
Sign up and explore now.
🔍 Learn more: Visit our blog and documents for more insights or schedule a demo to optimize your search solutions.
📬 Get in touch: Join our Discord community for help or Contact Us.
Stay Connected
💻 Website: nebulablock.com
📖 Docs: docs.nebulablock.com
🐦 Twitter: @nebulablockdata
🐙 GitHub: Nebula-Block-Data
🎮 Discord: Join our Discord
✍️ Blog: Read our Blog
📚 Medium: Follow on Medium
🔗 LinkedIn: Connect on LinkedIn
▶️ YouTube: Subscribe on YouTube