How to Build a Private RAG Pipeline on Nebula Block — No Data Leaves Canada

Retrieval-Augmented Generation (RAG) is one of the most practical AI patterns available right now. Instead of relying solely on what a model learned during training, RAG lets you attach your own documents, databases, and knowledge bases to the model — giving it accurate, current, proprietary information to work with.
The catch: most RAG architectures rely on US-based cloud infrastructure or external APIs. If your organization operates under Canadian data residency requirements — PIPEDA, Quebec's Law 25, or sector-specific rules in healthcare or finance — that's a major compliance bottleneck.
This guide outlines the strategic architecture to build a complete, production-ready, private RAG pipeline on Nebula Block (a Canadian GPU cloud provider), ensuring no enterprise data leaves the country at any stage.
Architecture Overview
To guarantee strict data residency, every single component of the 5-stage RAG pipeline must be hosted locally on Canadian sovereign infrastructure:
- Document Ingestion: Local parsing and chunking of proprietary files (PDFs, DOCX).
- Embedding Model: A locally hosted AI model converts text chunks into mathematical vectors—zero external API calls.
- Vector Database: An isolated database instance to store and index these vectors securely.
- Retrieval: Semantic matching of user queries against the local vector store.
- Generation: A localized Large Language Model (LLM) processing the retrieved context to generate the final answer within your secured network perimeter.
Infrastructure & Tech Stack
Instead of relying on third-party SaaS (like OpenAI or Pinecone), this architecture leverages an entirely open-source, self-hosted stack deployed on Nebula Block (Region: ca-central-1) using a dedicated, non-shared GPU instance (e.g., NVIDIA A100 or RTX 4090):
- Vector Database: Qdrant (Deployed via an isolated local Docker container with persistent storage).
- Embedding Model: BAAI/bge-large-en-v1.5 (A high-performance open-source model running locally on the GPU to generate 1024-dimensional semantic vectors).
- Language Model (LLM): Mistral-7B-Instruct-v0.3 (Quantized to 4-bit to optimize GPU memory footprint while maintaining enterprise-grade reasoning capabilities).
- Application Layer: FastAPI & Uvicorn (To encapsulate the pipeline into a secure internal API).
Technical Workflow
1. Secure Data Ingestion & Embedding
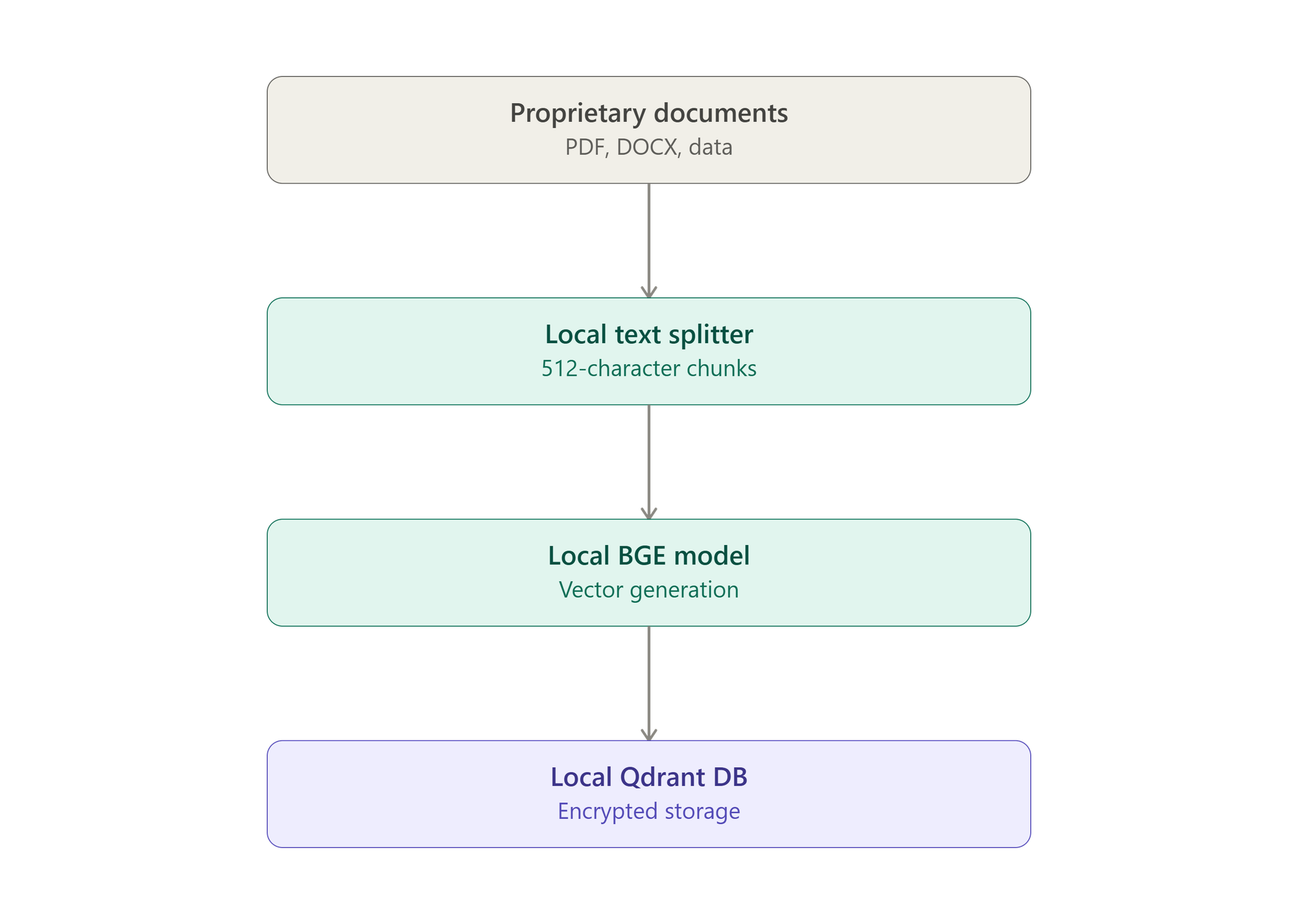
Documents are processed entirely in-memory. Text is broken down into structured chunks using smart overlapping to preserve context. The local BGE model encodes these chunks into vectors, which are then upserted directly into the local Qdrant instance. No data touches the public internet.
2. Isolated Retrieval & Generation
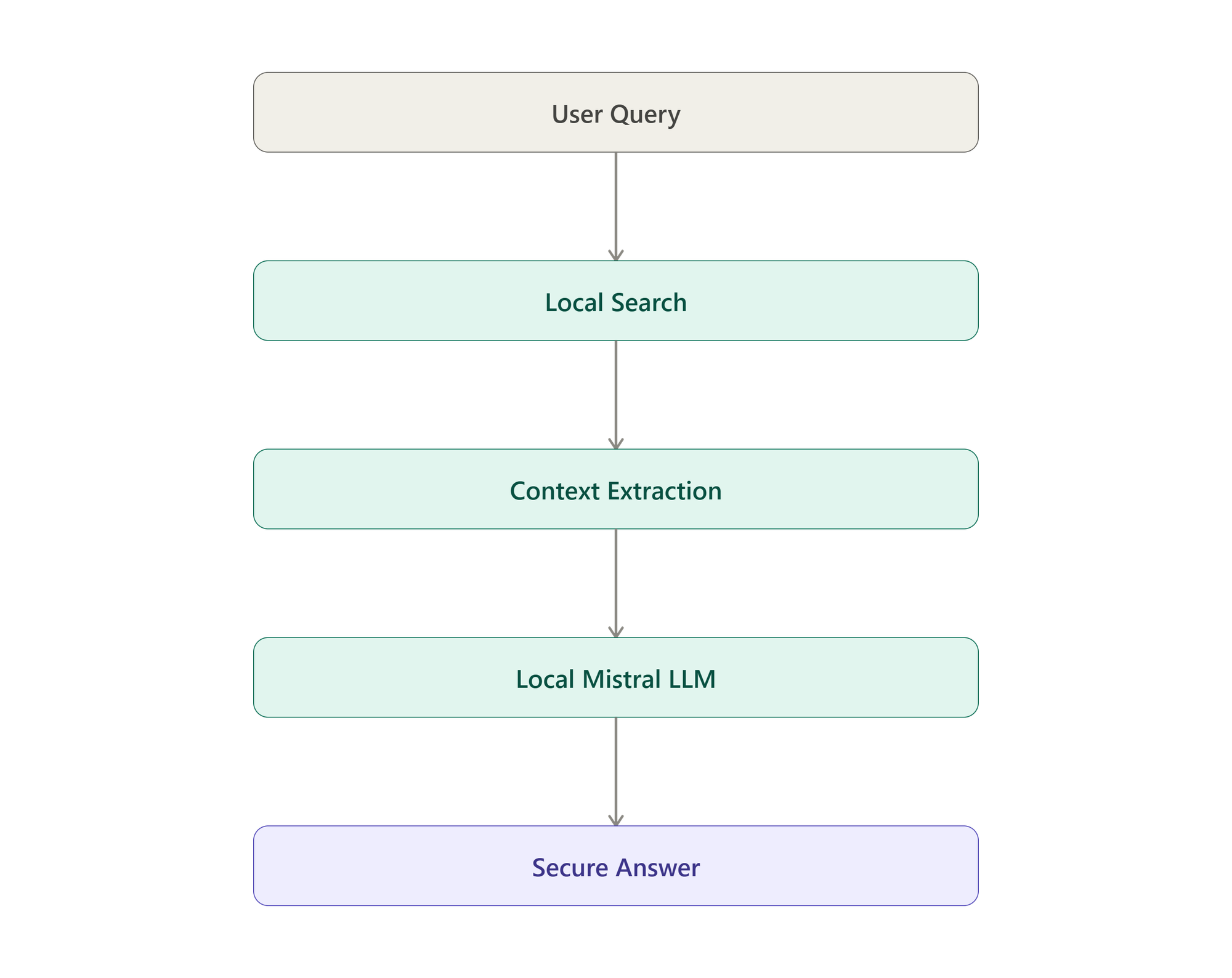
When a user submits a query, the system converts it into a vector using the same local embedding model. Qdrant performs a high-speed mathematical cosine similarity search to retrieve the top-k most relevant text chunks.
These chunks are injected into a strict prompt template inside the secured parameter:
System Prompt: You are a helpful assistant. Answer the question using ONLY the provided context. Context: [Retrieved Canadian-hosted document chunks] Question: [User Query]
The local Mistral-7B model processes this prompt completely offline on the dedicated GPU, ensuring the output is generated purely based on your secure knowledge base.
Enterprise Integration: Secure API
The entire pipeline is wrapped into an internal microservice using FastAPI. This allows internal company applications (such as proprietary CRMs, internal HR portals, or secure enterprise chatbots) to interact with the RAG system via secure, localized network requests.
To ensure production-grade compliance, the API endpoint is hardened behind Nebula Block's private firewalls, allowing access exclusively through corporate VPNs or internal IP whitelists, accompanied by robust API key token authentication.
Business Outcomes
By deploying this architecture, your organization achieves:
- Absolute Data Sovereignity: 100% compliance with PIPEDA and Quebec's Law 25.
- Zero Data Leakage: Eliminates the risk of vendor lock-in or proprietary data being used to train public commercial AI models.
- Predictable Cost Structure: Avoids unpredictable token-based API pricing in favor of flat-rate dedicated GPU cloud infrastructure.
Learn more at
- Email: contact@nebulablock.com
- Website: nebulablock.com
- Docs: docs.nebulablock.com
- Book a call: nebulablock.com/contact