Bill 25 Decoded: How Canadian LLM Deployments Must Adapt to Stay Compliant

Regulatory scrutiny on artificial intelligence is no longer theoretical. In Canada, Quebec's Bill 25 has moved from policy to active enforcement — and the organizations that assumed compliance was primarily a legal team problem are finding out, the hard way, that it was an infrastructure problem all along.
The Reality: An Infrastructure Problem Disguised as a Legal Issue
The core issue is not whether your organization intends to protect personal data. The issue is whether your AI stack is architecturally capable of proving it.
When your LLM processes a customer query, a financial record, or a health file — where does that inference run, who can legally access that compute environment, and can you document the answer clearly enough for a regulator?
For most enterprises running generative AI on public cloud infrastructure, that question does not have a clean answer. Bill 25 requires one.
The Core Pillars of Bill 25 Affecting Enterprise AI
Bill 25 carries real financial weight: up to CAD $25 million or 4% of global turnover for non-compliance. But the more immediate challenge for AI teams is operational. Three specific mandates require structural attention before your next deployment.
The Right to Erasure. When a Canadian consumer requests deletion of their personal data, that request does not stop at your application database. It extends to every system where that data may have been processed or retained — and for LLM deployments, that list is longer than most teams realize.
Vector databases built from customer documents may hold PII in embedded form. Fine-tuning datasets that included personal information cannot be cleanly "unlearned" without full retraining. Cached prompt histories and conversation logs carry identifiable information across sessions. Deleting a row in a relational database does not satisfy this obligation. You need to know exactly where personal data has traveled through your AI stack — and be able to act on that knowledge precisely.
Mandatory Privacy Impact Assessments. Before deploying any LLM infrastructure that handles personal information about Quebec residents, organizations must complete a Privacy Impact Assessment. This applies to new deployments, significant changes to existing systems, and any new third-party integrations — it is not a one-time exercise.
The PIA must demonstrate two things that are particularly difficult on public cloud infrastructure: that the data flow is fully traceable from ingestion through inference and output, and that no cross-border transfer occurs without documented justification. That second requirement is where most PIAs against US-headquartered providers run into trouble. The physical location of the server is not the same as its legal jurisdiction — a distinction that matters enormously under Bill 25.
Accountability That Survives an Audit. Bill 25 requires organizations to maintain clear, demonstrable records of who processes personal information, on what infrastructure, and under which legal framework. Not as a description of intended practice — as documented operational reality. For AI pipelines and autonomous agentic workflows spanning multiple vendors, APIs, and cloud services, building that documentation retroactively is painful. The organizations that clear regulatory review fastest are the ones that designed accountability into the stack before deployment, not after.
The Public Cloud Problem: Cross-Border API Leaks
Reality Check: Every time your application sends a prompt to a third-party model API, a cross-border data transfer occurs. Under Bill 25, if that transfer was not covered by a PIA and explicit informed consent, it is a compliance breach. Most organizations running AI in production are doing this at scale, continuously, without realizing it.
Under the US CLOUD Act, US-headquartered companies can be legally compelled to produce data held anywhere in the world. Routing a Canadian customer's personal information through a US-based model API — even briefly, even in transit — creates jurisdictional exposure that no data processing agreement can fully override. The migration path regulated Canadian enterprises are taking is straightforward: move inference to sovereign, self-hosted open-weight models on domestic GPU infrastructure, so data never leaves Canadian jurisdiction at any layer of the stack.
Building a Bill 25-Compliant AI Pipeline
Compliance does not mean slowing down. It means designing the stack correctly from the start so you never have to re-architect it under pressure. A Bill 25-ready pipeline runs on three layers.
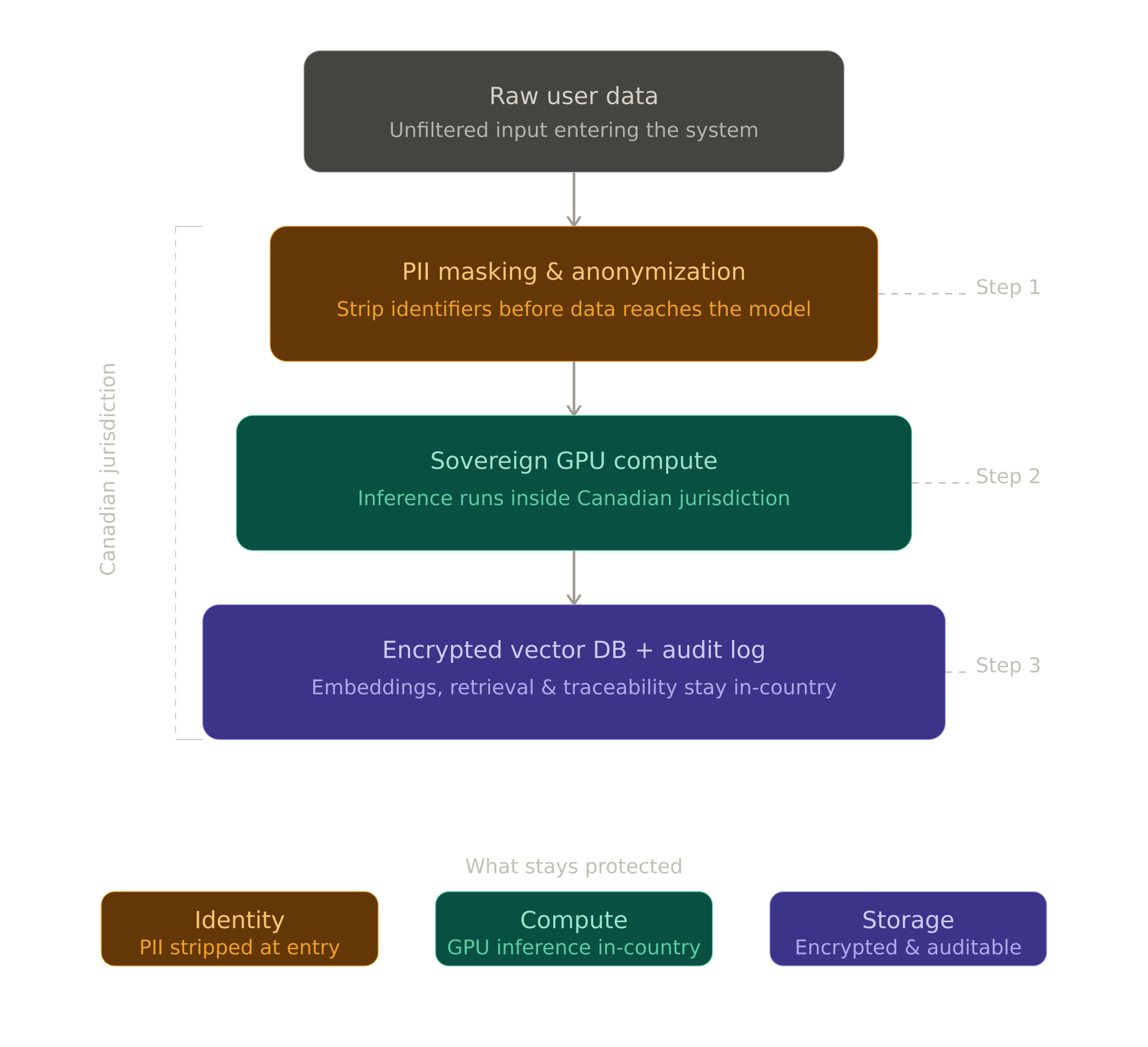
- Anonymization at the edge. Implement tokenization and PII scrubbing before any prompt reaches the LLM context window. Named entity recognition handles names, addresses, health identifiers, and financial data. What never reaches the model as PII cannot create erasure or accountability problems downstream.
- Sovereign hosting. Host your open-weight models on dedicated Canadian infrastructure outside the jurisdictional reach of foreign governments. On Nebula Block, that means NVIDIA H100, H200, and next-generation Blackwell GB300 GPU instances inside Canadian data centers, under 100% Canadian corporate ownership — no US parent entity, no CLOUD Act exposure. Every prompt, retrieved document, and intermediate reasoning step stays in Canada. For your PIA, there is no cross-border transfer to assess and no residual jurisdictional risk to disclose.
- Immutable audit logging. Maintain isolated log systems that track how data moves at every stage — what came in, what was masked, what reached the model, and what was returned. This is the evidence base for regulatory audits and the operational foundation for responding to right-to-erasure requests with actual precision, not best-effort estimates.
Compliance as Competitive Advantage
The organizations treating Bill 25 as a barrier are re-architecting mid-deployment, under pressure, at significant cost. The organizations that treated it as a design constraint from the beginning are closing enterprise deals faster, clearing regulatory review with less friction, and building a customer trust story that competitors on non-sovereign infrastructure simply cannot match.
Sovereign AI infrastructure is not a compliance overhead. It is the foundation that makes serious enterprise AI possible in Canada's regulated sectors — and the standard that procurement teams, auditors, and regulators are converging on.
Build on it now, before the first compliance review forces the issue.
Ready to build a Bill 25-compliant AI stack on Canada's sovereign GPU infrastructure?
- Email: contact@nebulablock.com
- Website: nebulablock.com
- Docs: docs.nebulablock.com
- Book a call: nebulablock.com/contact