Access LLaMA 3.3‑70B on Nebula Block in Minutes

Meta’s LLaMA 3.3-70B stands out as one of the most powerful open-source language models to date — blending world-class reasoning, speed, and scalability with a permissive license for commercial and research use.
In this quick-start guide, we’ll show you how to use LLaMA 3.3-70B on Nebula Block’s GPU-powered infrastructure — in under five minutes and with minimal DevOps setup.
Why LLaMA 3.3-70B?
LLaMA 3.3-70B delivers:
- 70 billion parameters optimized for inference speed and scalability.
- Top-tier reasoning, multilingual understanding, and coding capabilities.
- Open-weight availability with commercial-friendly licensing.
- Versatile fine-tuning and system integration potential.
With Nebula Block, you can seamlessly integrate the high-performance LLaMA 3.3-70B into your services:
- Pre-installed vLLM inference server for optimized performance.
- High-memory GPU machines (A100, H100) ready for large-scale inference.
- Built-in endpoint for easy API or LangChain integration.
- Minimal DevOps setup — fully scalable infrastructure.
- Your data stays yours — privacy-first design with encrypted inference and isolated GPU runtime
Get Started in Under 5 Minutes
1. Sign Up
Create an Account: Visit Nebula Block and signup to get access.
2. Send an Inference Request
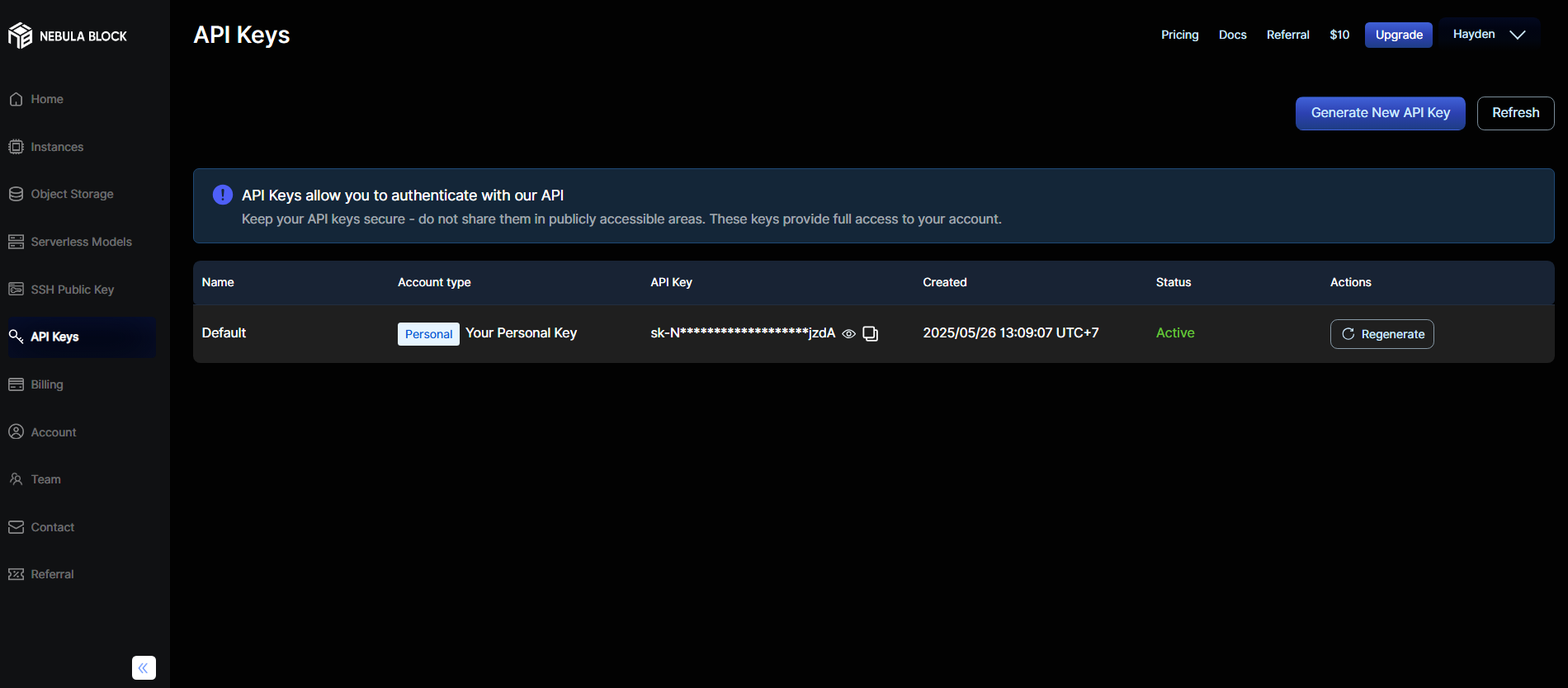
2.1 Get your API Key
Seclect API Keys tab, choose "Generate New API Key" if you don't have one:
2.2 Make a API Call
Choose LLaMA 3.3-70B in "Serverless Models" tab
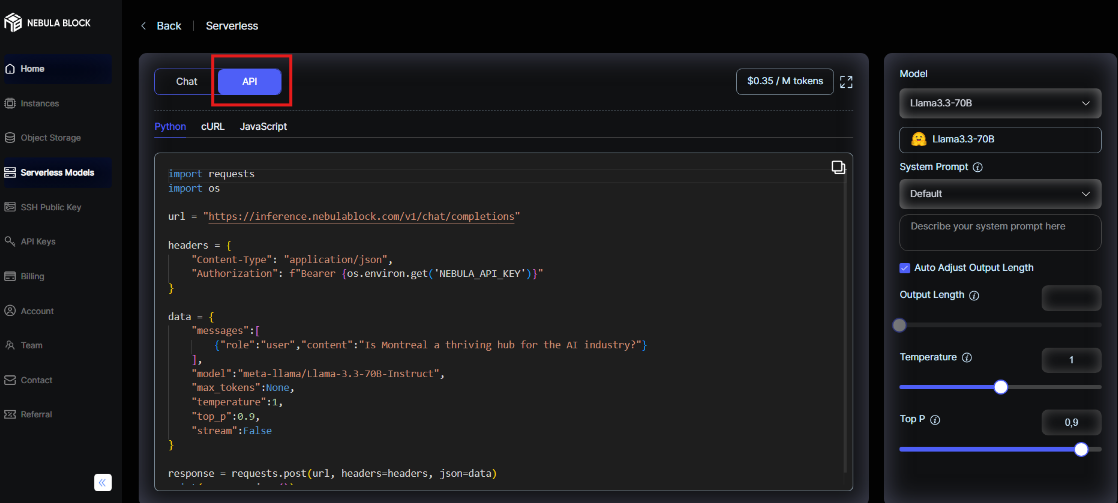
Use this API call to access the pre-provisioned model:
import requests
import os
url = "https://inference.nebulablock.com/v1/chat/completions"
headers = {
"Content-Type": "application/json",
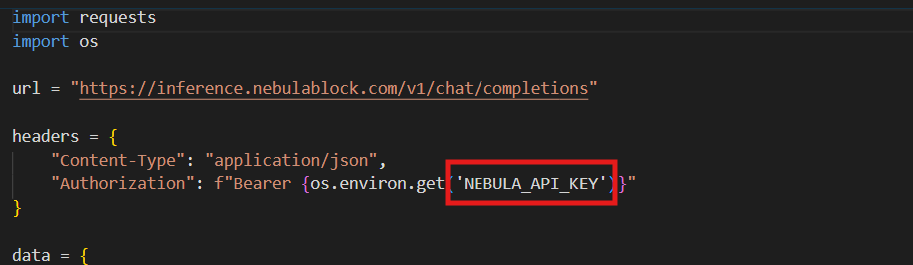
"Authorization": f"Bearer {os.environ.get('NEBULA_API_KEY')}"
}
data = {
"messages":[
{"role":"user","content":"Is Montreal a thriving hub for the AI industry?"}
],
"model":"meta-llama/Llama-3.3-70B-Instruct",
"max_tokens":512,
"temperature":1,
"top_p":0.9,
"stream":False
}
response = requests.post(url, headers=headers, json=data)
print(response.json())Paste your API Key here:
3. Error Handling in API Call
if response.status_code == 200:
print(response.json())
else:
print(f"Error: {response.status_code}, {response.text}")
4. Monitoring and Optimization
Nebula Block’s web dashboard and APIs track usage, response times, and costs. Optimize with:
- Token Limits: Set
max_tokens(e.g.,max_tokens: 1024for detailed answers) for longer control. - Temperature:
temperature: 0.7→ More deterministic responses.
temperature: 1.2→ More creative responses.top_p: 0.9→ Balanced sampling for diverse outputs.- Enable Streaming: Set
"stream": truefor real-time responses.
Real-World Applications
- Code Generation: Produces secure, documented code for production use.
- Business Analysis: Provides strategic insights for complex scenarios.
- Content Creation: Generates tailored technical documentation.
Conclusion
Nebula Block’s serverless AI infrastructure lets you run LLaMA 3.3-70B effortless, eliminating manual scaling, infrastructure setup, and GPU provisioning. Whether for semantic search, analytics, or AI-driven automation, Nebula Block provides a fast, cost-efficient way to harness large language models at scale.
Next Steps
Sign up and explore now.
🔍 Learn more: Visit our blog and documents for more insights or schedule a demo to optimize your search solutions.
📬 Get in touch: Join our Discord community for help or Contact Us.
Stay Connected
💻 Website: nebulablock.com
📖 Docs: docs.nebulablock.com
🐦 Twitter: @nebulablockdata
🐙 GitHub: Nebula-Block-Data
🎮 Discord: Join our Discord
✍️ Blog: Read our Blog
📚 Medium: Follow on Medium
🔗 LinkedIn: Connect on LinkedIn
▶️ YouTube: Subscribe on YouTube